La majorité des API se font désormais au format REST. Sous Django, de telles API peuvent facilement se créer grâce au toolkit Django REST framework.
Nous allons voir dans cet article comment créer une API REST sous Django. Pour que l’exemple soit ludique, nous créerons une API fournissant la liste complète des bières belge ! Pour cela nous utiliserons Scrapy afin de parser la page Wikipédia correspondante, puis nous utiliserons les modèles Django pour insérer les données en base.
Setup
On commence par créer un nouvel environnement virtuel qui contiendra l’ensemble des packages utiles à notre projet :
$ mkvirtualenv beer-rest
$ pip install Scrapy scrapy-djangoitem Django djangorestframework
Dans l’ordre :
- Scrapy va nous servir à parser la page Wikipédia et retourner les informations souhaitées,
- scrapy-djangoitem nous permettra d’utiliser les modèles Django dans notre projet Scrapy,
- Django sera notre framework web,
- djangorestframework va nous permettre de créer facilement notre API REST.
Nous pouvons maintenant créer notre projet Django alcohol, ainsi que l’application beer :
$ django-admin startproject alcohol
$ cd alcohol
$ ./manage.py startapp beer
Création du modèle
La page Wikipédia suivante propose la liste complète des bières belges, par ordre alphabétique.
Nous allons enregistrer en base les informations données, à savoir :
- le nom de la bière
- le type
- la teneur en alcool
- la brasserie
Voici le modèle correspondant :
# ./alcohol/beer/models.py
from django.db import models
class Beer(models.Model):
nom = models.CharField(max_length=80)
type = models.CharField(max_length=30)
degre = models.CharField(max_length=6, null=True)
brasserie = models.CharField(max_length=80)
def __str__(self):
return self.nom
Certaines teneurs en alcool ne sont pas mentionnées, nous autorisons donc la valeur null.
On active cette application dans le fichier settings.py de notre projet Django :
# ./alcohol/alcohol/settings.py
INSTALLED_APPS = (
...
'beer'
)
On synchronise ensuite la base de données :
$ ./manage.py makemigrations
$ ./manage.py migrate
Récupération des bières avec Scrapy
Nous allons utiliser Scrapy pour extraire les données et les insérer en base.
Toujours dans le dossier alcohol, nous créons un dossier scrapy qui contiendra nos crawlers (nous n’en aurons qu’un dans notre cas), puis nous initialisons un nouveau projet Scrapy :
$ mkdir scrapy
$ cd scrapy
$ scrapy startproject wikibeer
$ cd wikibeer
Nous devrions normalement créer une sous-classe de scrapy.Item, contenant la liste des données souhaitées (nom, type, degre, brasserie). Néanmoins nous voulons que les données récupérées par Scrapy soient directement accessible via Django. Pour cela nous allons utiliser le package scrapy-djangoitem qui se chargera lui-même d’insérer les éléments en base.
Voici donc à quoi ressemble notre classe item :
# -*- coding: utf-8 -*-
# ./alcohol/scrapy/wikibeer/wikibeer/items.py
from scrapy_djangoitem import DjangoItem
from beer.models import Beer
class WikibeerItem(DjangoItem):
django_model = Beer
L’accès au modèle Beer de notre projet Django est rendu possible en ajoutant les lignes suitantes au fichier settings.py de votre projet Scrapy :
# -*- coding: utf-8 -*-
# ./alcohol/scrapy/wikibeer/wikibeer/settings.py
import sys
sys.path.append('/opt/projects/alcohol')
import os
os.environ['DJANGO_SETTINGS_MODULE'] = 'alcohol.settings'
...
Pensez à modifier le chemin selon votre configuration.
Il ne reste plus qu’à créer notre spider qui se chargera de retourner les données contenues dans la page :
# -*- coding: utf-8 -*-
# ./alcohol/scrapy/wikibeer/wikibeer/spiders/wikibeer_spider.py
import scrapy
from wikibeer.items import WikibeerItem
class WikibeerSpider(scrapy.Spider):
name = "wikibeer"
allowed_domains = ["fr.wikipedia.org"]
start_urls = [
"https://fr.wikipedia.org/wiki/Liste_des_bi%C3%A8res_belges",
]
def parse(self, response):
for sel in response.xpath('//table[contains(@class, "wikitable")]//tr'):
# On vérifie qu'il ne s'agit pas du header du tableau
nom = sel.xpath('td[1]//text()').extract()
if not nom:
continue
item = WikibeerItem()
item['nom'] = "".join(nom)
item['type'] = "".join(sel.xpath('td[2]//text()').extract())
item['degre'] = "".join(sel.xpath('td[3]//text()').extract())
item['brasserie'] = "".join(sel.xpath('td[4]//text()').extract())
item.save()
Je ne m’attarde pas sur ce code, n’hésitez pas à jeter un oeil à la documentation de Scrapy si vous voulez plus d’informations. Scrapy est un crawler web extrèmement puissant, et le spider précédent n’exploite qu’une infime partie de ses possibilités.
Notez tout de même l’utilisation de la méthode save() sur l’item (plutôt que de le renvoyer via un yield) qui permet d’enregistrer l’objet en base.
Le spider peut enfin être lancé grâce à la commande suivante :
$ scrapy crawl wikibeer
2015-08-27 18:23:50 [scrapy] INFO: Scrapy 1.0.1 started (bot: wikibeer)
2015-08-27 18:23:50 [scrapy] INFO: Optional features available: ssl, http11
2015-08-27 18:23:50 [scrapy] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'wikibeer.spiders', 'SPIDER_MODULES': ['wikibeer.spiders'], 'BOT_NAME': 'wikibeer'}
2015-08-27 18:23:50 [scrapy] INFO: Enabled extensions: CloseSpider, TelnetConsole, LogStats, CoreStats, SpiderState
2015-08-27 18:23:50 [scrapy] INFO: Enabled downloader middlewares: HttpAuthMiddleware, DownloadTimeoutMiddleware, UserAgentMiddleware, RetryMiddleware, DefaultHeadersMiddleware, MetaRefreshMiddleware, HttpCompressionMiddleware, RedirectMiddleware, CookiesMiddleware, ChunkedTransferMiddleware, DownloaderStats
2015-08-27 18:23:50 [scrapy] INFO: Enabled spider middlewares: HttpErrorMiddleware, OffsiteMiddleware, RefererMiddleware, UrlLengthMiddleware, DepthMiddleware
2015-08-27 18:23:50 [scrapy] INFO: Enabled item pipelines:
2015-08-27 18:23:50 [scrapy] INFO: Spider opened
2015-08-27 18:23:50 [scrapy] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2015-08-27 18:23:51 [scrapy] DEBUG: Telnet console listening on 127.0.0.1:6023
2015-08-27 18:23:51 [scrapy] DEBUG: Crawled (200) <GET https://fr.wikipedia.org/wiki/Liste_des_bi%C3%A8res_belges> (referer: None)
2015-08-27 18:23:52 [django.db.backends] DEBUG: (0.000) QUERY = u'BEGIN' - PARAMS = (); args=None
2015-08-27 18:23:52 [django.db.backends] DEBUG: (0.001) QUERY = u'INSERT INTO "beer_beer" ("nom", "type", "degre", "brasserie") VALUES (%s, %s, %s, %s)' - PARAMS = (u'3 Scht\xe9ng', u'Fermentation haute', u'6\xa0%', u"Brasserie Grain d'Orge"); args=[u'3 Scht\xe9ng', u'Fermentation haute', u'6\xa0%', u"Brasserie Grain d'Orge"]
2015-08-27 18:23:52 [scrapy] INFO: Received SIGINT, shutting down gracefully. Send again to force
2015-08-27 18:23:52 [django.db.backends] DEBUG: (0.000) QUERY = u'BEGIN' - PARAMS = (); args=None
2015-08-27 18:23:52 [django.db.backends] DEBUG: (0.000) QUERY = u'INSERT INTO "beer_beer" ("nom", "type", "degre", "brasserie") VALUES (%s, %s, %s, %s)' - PARAMS = (u'IV Saison', u'Saison', u'6,5\xa0%', u'Brasserie de Jandrain-Jandrenouille'); args=[u'IV Saison', u'Saison', u'6,5\xa0%', u'Brasserie de Jandrain-Jandrenouille']
2015-08-27 18:23:52 [django.db.backends] DEBUG: (0.000) QUERY = u'BEGIN' - PARAMS = (); args=None
2015-08-27 18:23:52 [django.db.backends] DEBUG: (0.000) QUERY = u'INSERT INTO "beer_beer" ("nom", "type", "degre", "brasserie") VALUES (%s, %s, %s, %s)' - PARAMS = (u'V Cense', u'Fermentation haute, Sp\xe9ciale', u'7,5\xa0%', u'Brasserie de Jandrain-Jandrenouille'); args=[u'V Cense', u'Fermentation haute, Sp\xe9ciale', u'7,5\xa0%', u'Brasserie de Jandrain-Jandrenouille']
2015-08-27 18:23:52 [django.db.backends] DEBUG: (0.000) QUERY = u'BEGIN' - PARAMS = (); args=None
2015-08-27 18:23:52 [django.db.backends] DEBUG: (0.000) QUERY = u'INSERT INTO "beer_beer" ("nom", "type", "degre", "brasserie") VALUES (%s, %s, %s, %s)' - PARAMS = (u'VI Wheat', u'Fermentation haute, Blanche', u'6\xa0%', u'Brasserie de Jandrain-Jandrenouille'); args=[u'VI Wheat', u'Fermentation haute, Blanche', u'6\xa0%', u'Brasserie de Jandrain-Jandrenouille']
2015-08-27 18:23:52 [django.db.backends] DEBUG: (0.000) QUERY = u'BEGIN' - PARAMS = (); args=None
2015-08-27 18:23:52 [django.db.backends] DEBUG: (0.000) QUERY = u'INSERT INTO "beer_beer" ("nom", "type", "degre", "brasserie") VALUES (%s, %s, %s, %s)' - PARAMS = (u'26.2 M', u'Blonde', u'4,8\xa0%', u"Brasserie L'\xc9chapp\xe9e Belle"); args=[u'26.2 M', u'Blonde', u'4,8\xa0%', u"Brasserie L'\xc9chapp\xe9e Belle"]
...
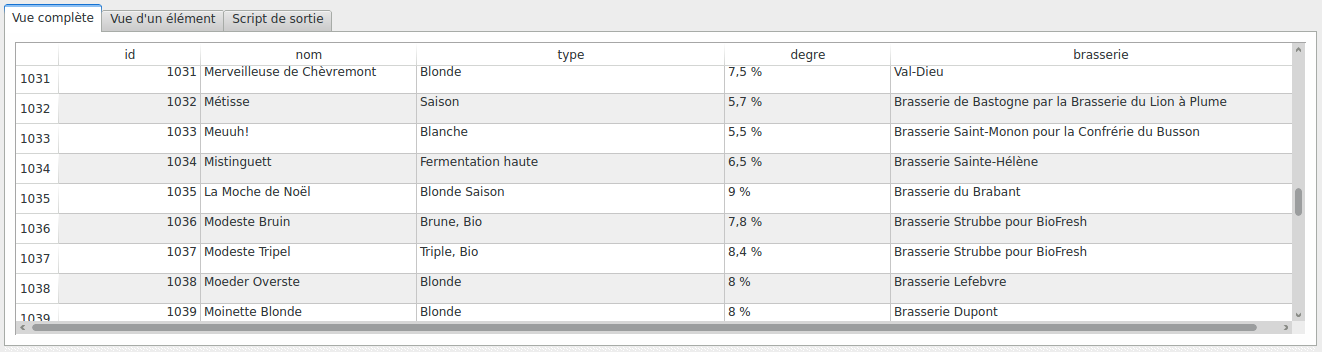
Les données sont bien enregistrées en base de données, le tout en passant par notre modèle Django :
Mise en place de Django Rest Framework
Nous avons maintenant la liste entière des bières dans notre base de données. Nous pouvons créer un serializer basé sur notre modèle Beer :
# ./alcohol/beer/serializers.py
from beer.models import Beer
from rest_framework import serializers
class BeerSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = Beer
fields = ('nom', 'type', 'degre', 'brasserie')
Nous créons ensuite une vue qui sera une sous-classe de rest_framework.viewsets.ModelViewSet dans laquelle nous renseignons la requête utilisée (toutes les bières) et le serializer créé précédemment :
# ./alcohol/beer/views.py
from rest_framework import viewsets
from beer.models import Beer
from beer.serializers import BeerSerializer
class BeerViewSet(viewsets.ModelViewSet):
queryset = Beer.objects.all()
serializer_class = BeerSerializer
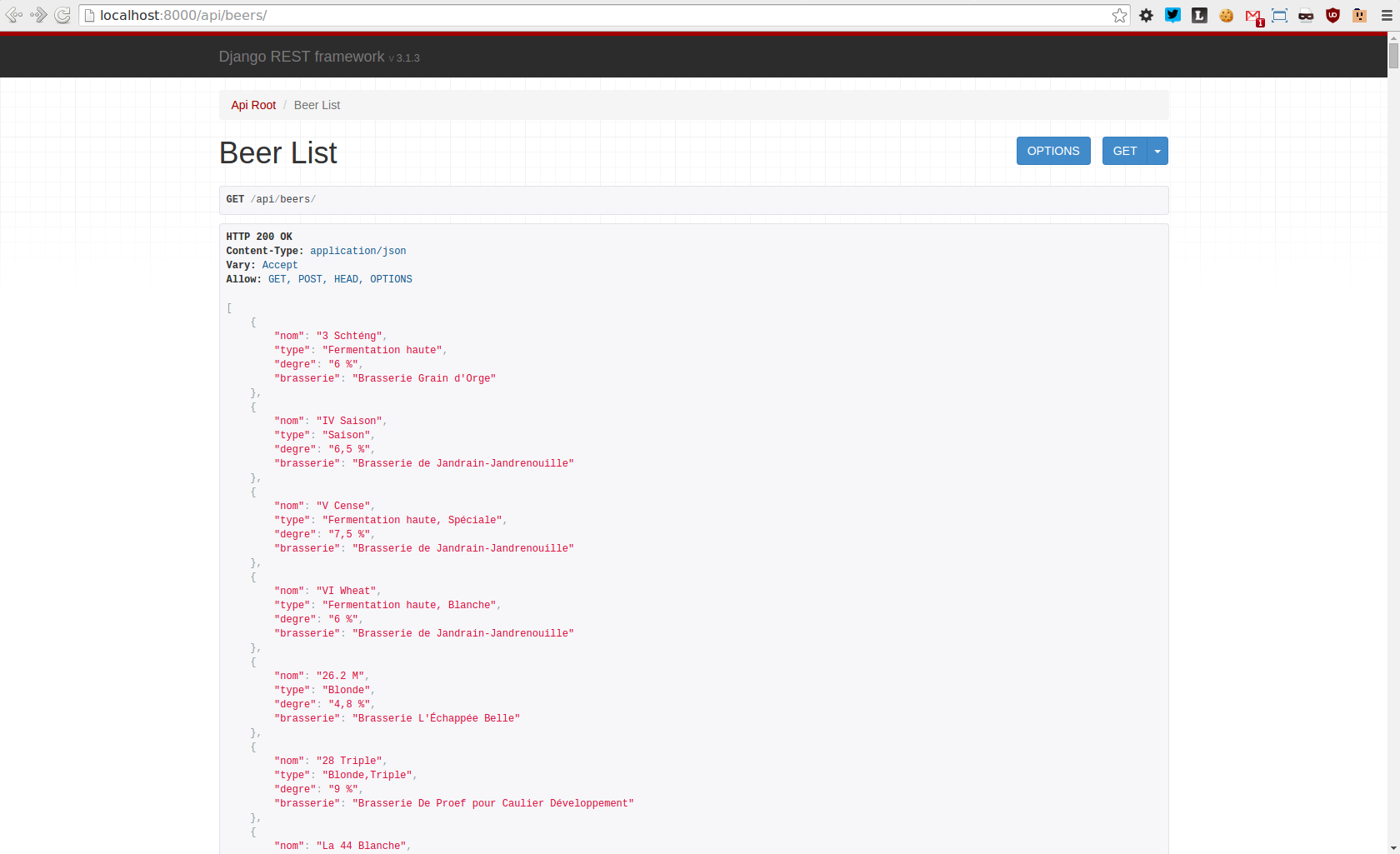
Les urls de notre projet doivent être renseignées dans le fichier alcohol/urls.py (dans notre cas l’API sera accessible via http://localhost:8000/api/beers/ :
# ./alcohol/alcohol/urls.py
from django.contrib import admin
from django.conf.urls import url, include
from rest_framework import routers
from beer.views import BeerViewSet
router = routers.DefaultRouter()
router.register(r'api/beers', BeerViewSet)
urlpatterns = [
url(r'^admin/', include(admin.site.urls)),
url(r'^', include(router.urls))
]
Il ne reste plus qu’à activer l’application Django Rest Framework dans le fichier settings.py de notre projet Django :
# ./alcohol/alcohol/settings.py
INSTALLED_APPS = (
...
'rest_framework',
'beer'
)
Test de l’API
Et voilà ! Nous avons rapratrier un jeu de données via Scrapy, nous avons mis en place notre API via Django Rest Framework, nous pouvons désormais la tester.
On lance tout d’abord le serveur :
$ ./manage.py runserver
Performing system checks...
System check identified no issues (0 silenced).
August 27, 2015 - 18:28:08
Django version 1.8.4, using settings 'alcohol.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.
Puis nous utilisons curl (par exemple) pour accéder à notre API :
$ curl -H 'Accept: application/json; indent=4' http://127.0.0.1:8000/api/beers/
...
{
"nom": "Abbaye du Park Blonde",
"type": "Abbaye, Blonde",
"degre": "6 %",
"brasserie": "Brasserie Haacht"
},
{
"nom": "Abbaye du Park Brune",
"type": "Abbaye, Brune",
"degre": "6 %",
"brasserie": "Brasserie Haacht"
},
{
"nom": "Abdis Blond",
"type": "Blonde",
"degre": "6,5 %",
"brasserie": "Brasserie Riva"
},
{
"nom": "Abdis Bruin",
"type": "Brune",
"degre": "6,5 %",
"brasserie": "Brasserie Riva"
}
...
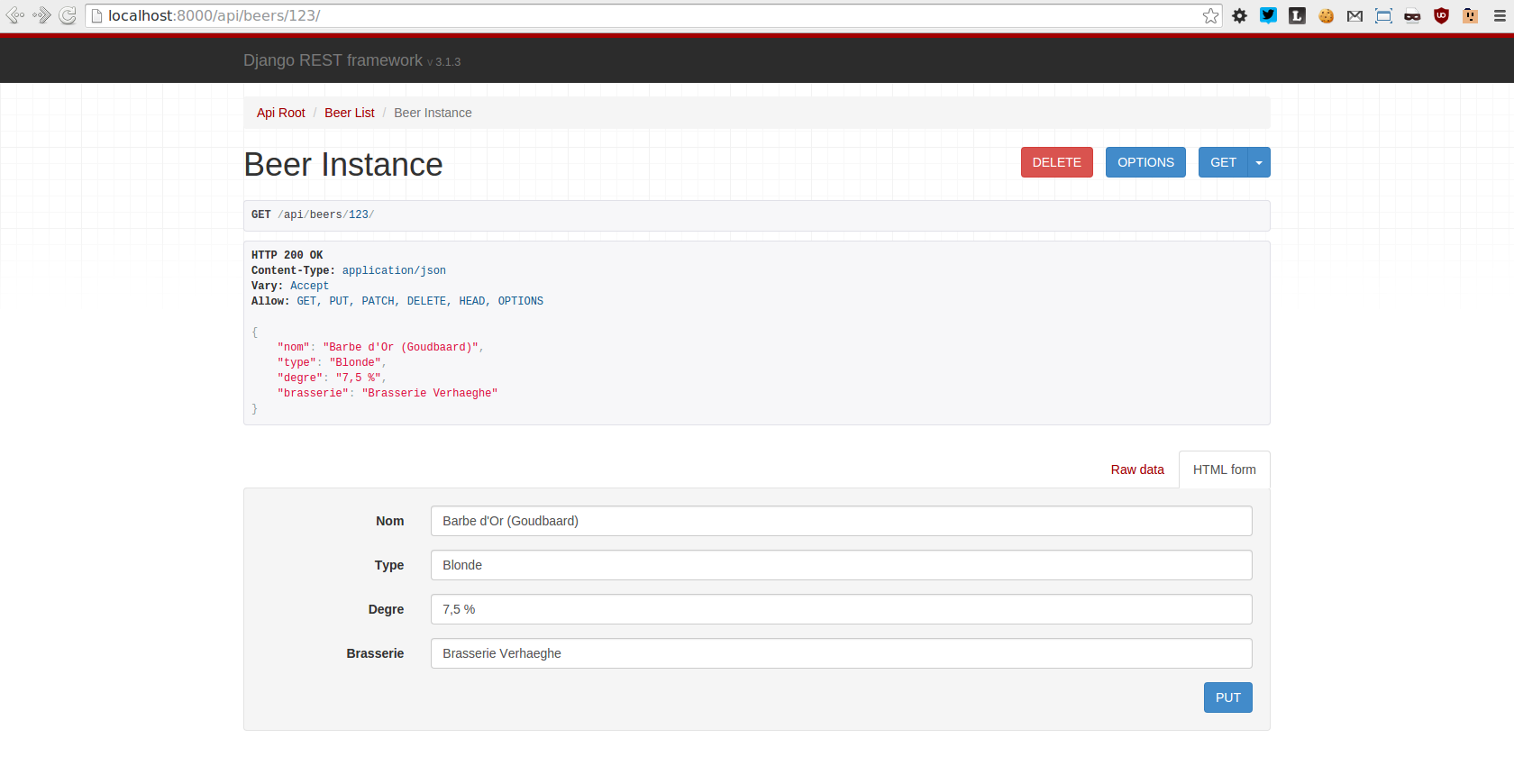
Notez pour finir que Django Rest Framework fournit également une interface web pour consulter votre API :