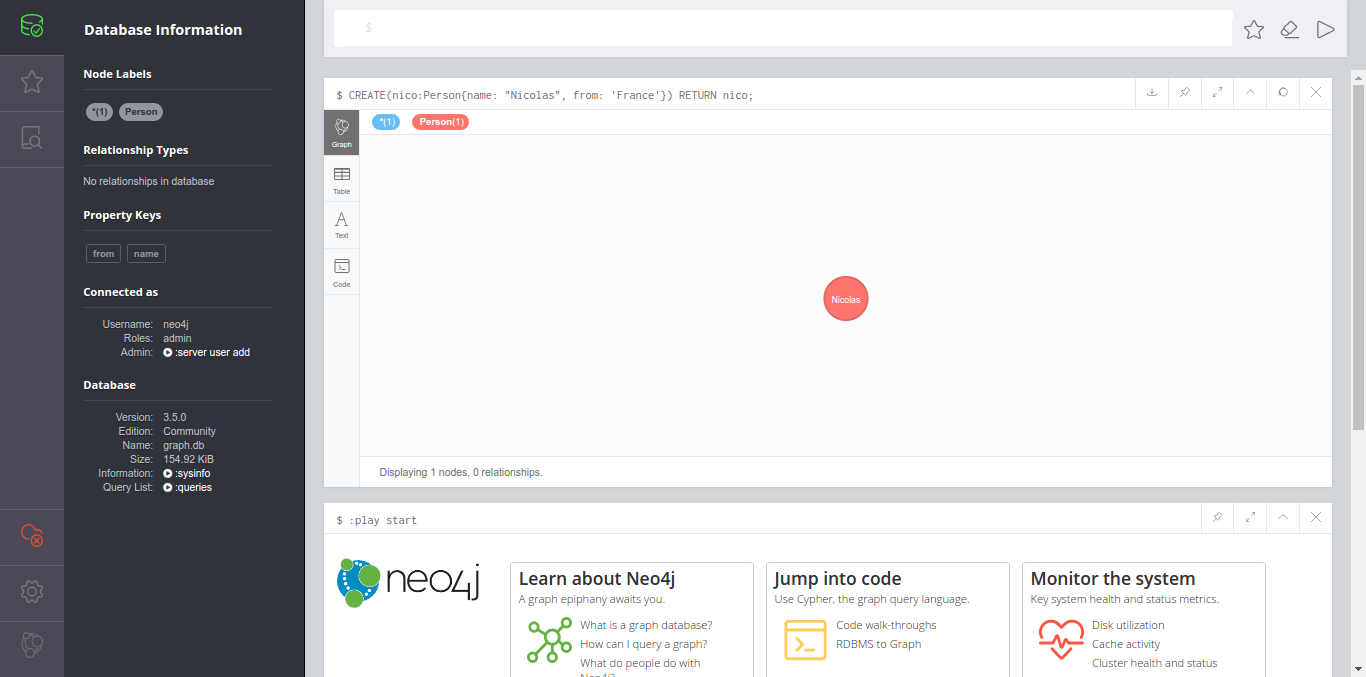
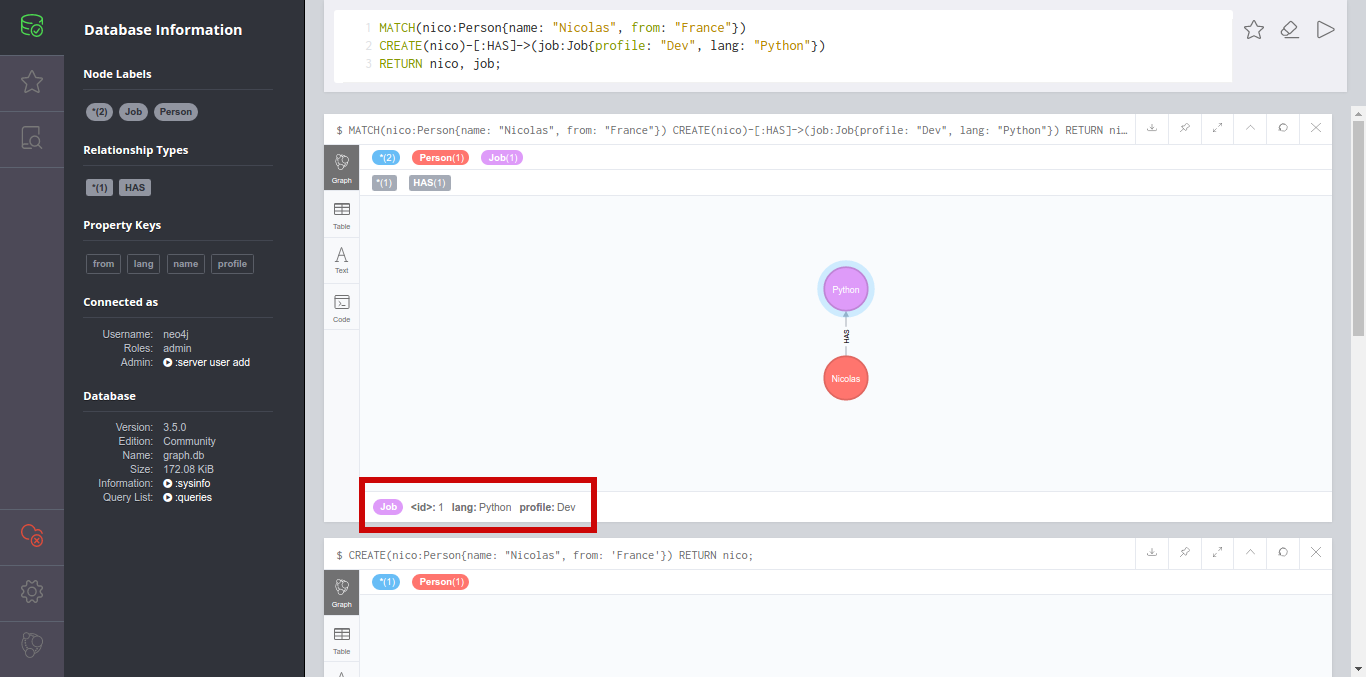
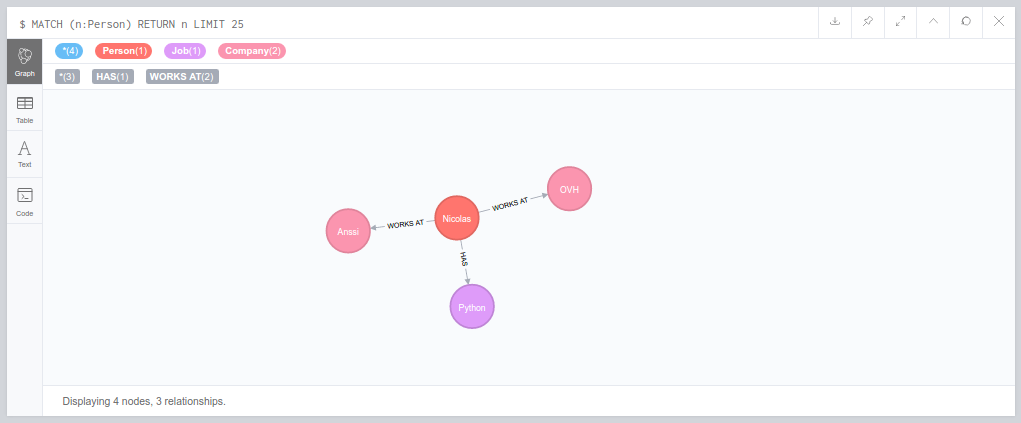
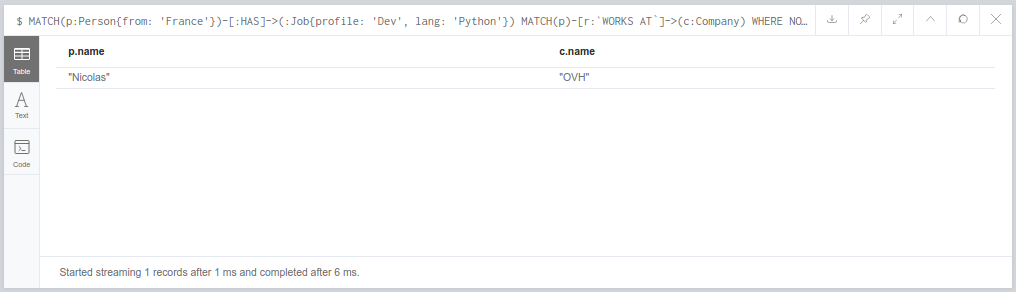
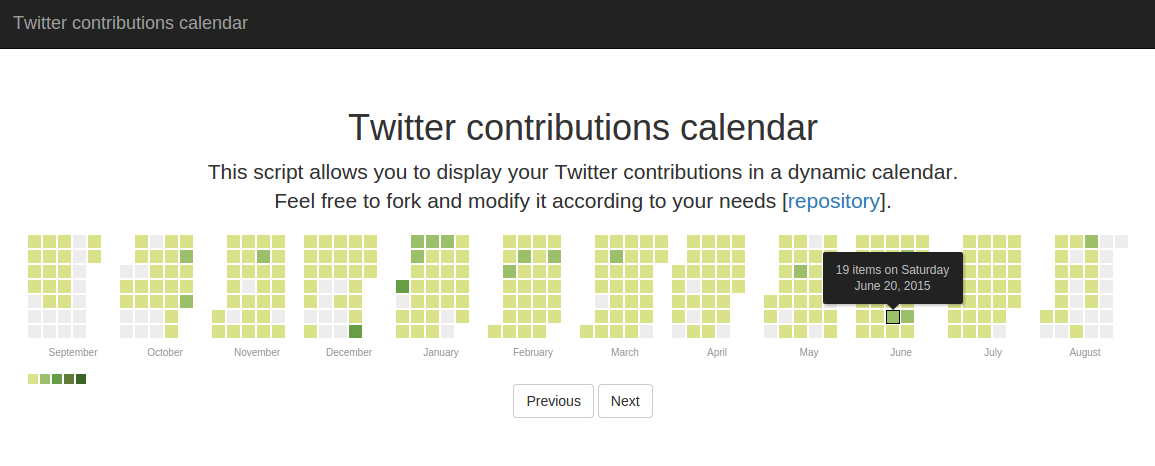
Apache Airflow est un outil open source d’orchestration de workflows : si vous êtes habitués à gérer des tâches cron au quotidien, alors cet article devrez vous plaire.
Airflow vs. Cron
Pour l’histoire Airflow a été créé en 2014 par Maxime Beauchemin lorsqu’il travaillait chez Airbnb. En 2016 le projet a rejoint le programme d’incubation de la fondation Apache, c’est pourquoi nous parlons désormais d’Apache Airflow.

Alors qu’est-ce qui le différencie des tâches cron ? Après tout nous y sommes habitués, et il faut avouer qu’il est très simple de lancer de manière régulière un script, une commande ou un programme.
Mais il y a fort à parier que votre tâche rencontrera tôt ou tard un problème :
- un timeout sur une requête SQL,
- un changement de clé dans le Json d’une API que vous interrogez,
- un site web injoignable au moment d’un GET,
- etc.
A la limite si notre script est très simple nous pouvons gérer ces cas dans le code lui-même, il ne faudra en oublier aucun, mais ça reste faisable.
En revanche les choses se compliquent lorsque nous devons gérer plusieurs tâches dépendantes les unes des autres. Imaginez qu’une tâche B ait besoin de données créées par une tâche A, elle doit donc s’exécuter après. En cron nous laisserions un temps raisonnable entre le lancement des 2 tâches pour que celles-ci s’exécutent correctement. Sauf que ce laps de temps est fixé, si la tâche A plante pour une raison ou une autre, la tâche B s’exécutera tout de même avec potentiellement des données corrompues.
C’est là qu’Airflow entre en jeu : cet outil va justement nous permettre de gérer les dépendances entre nos tâches, on parle alors de workflow ou encore de pipeline. Nous déclarons nos tâches à Airflow, et ce dernier s’occupe de les lancer dans le bon ordre, de gérer les exceptions s’il y en a, et de relancer les tâches le cas échéant.
En bonus Airflow est livré avec une Webui extrêmement pratique qui va nous permettre de suivre l’avancement de nos tâches et de les monitorer :
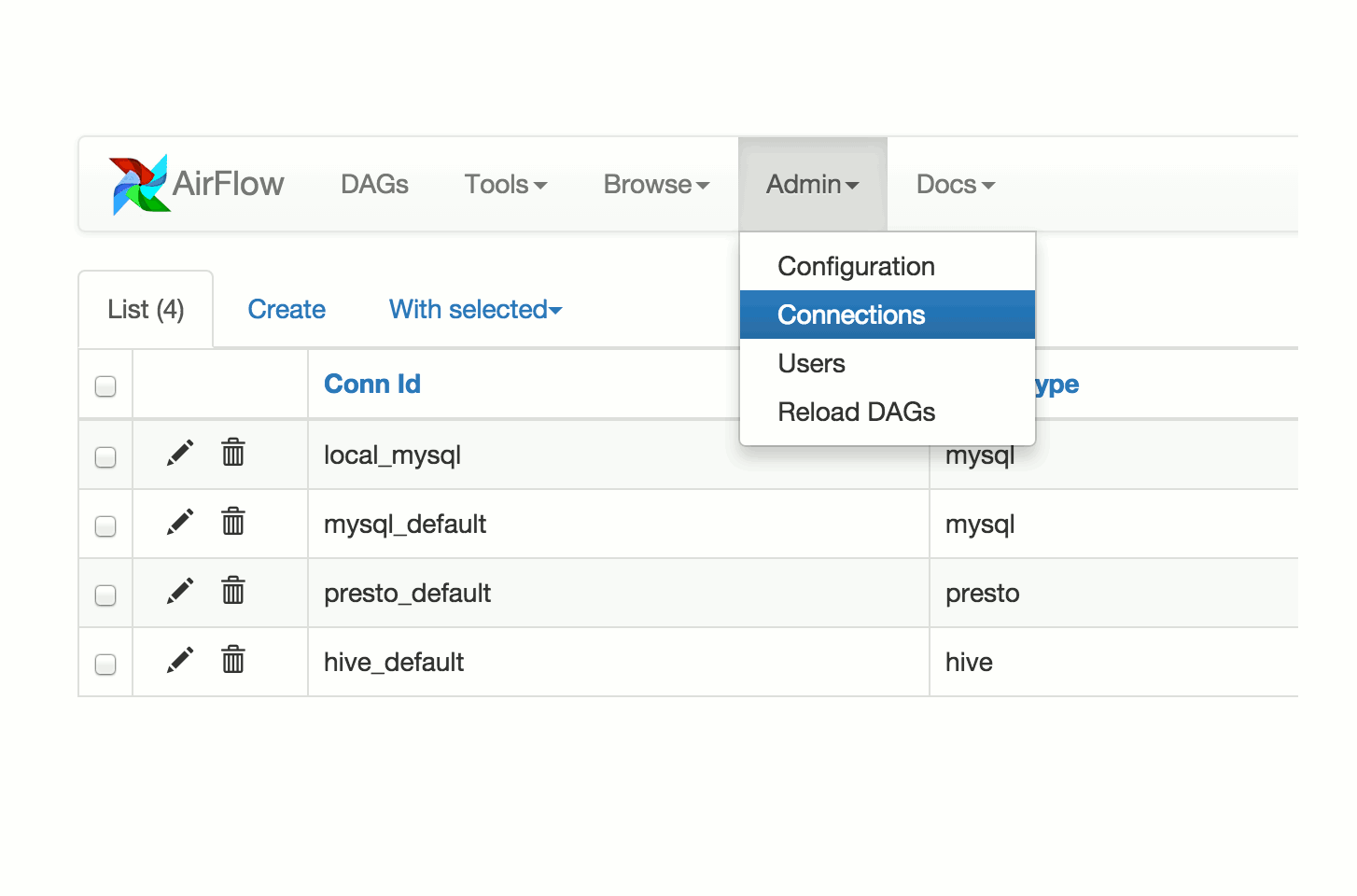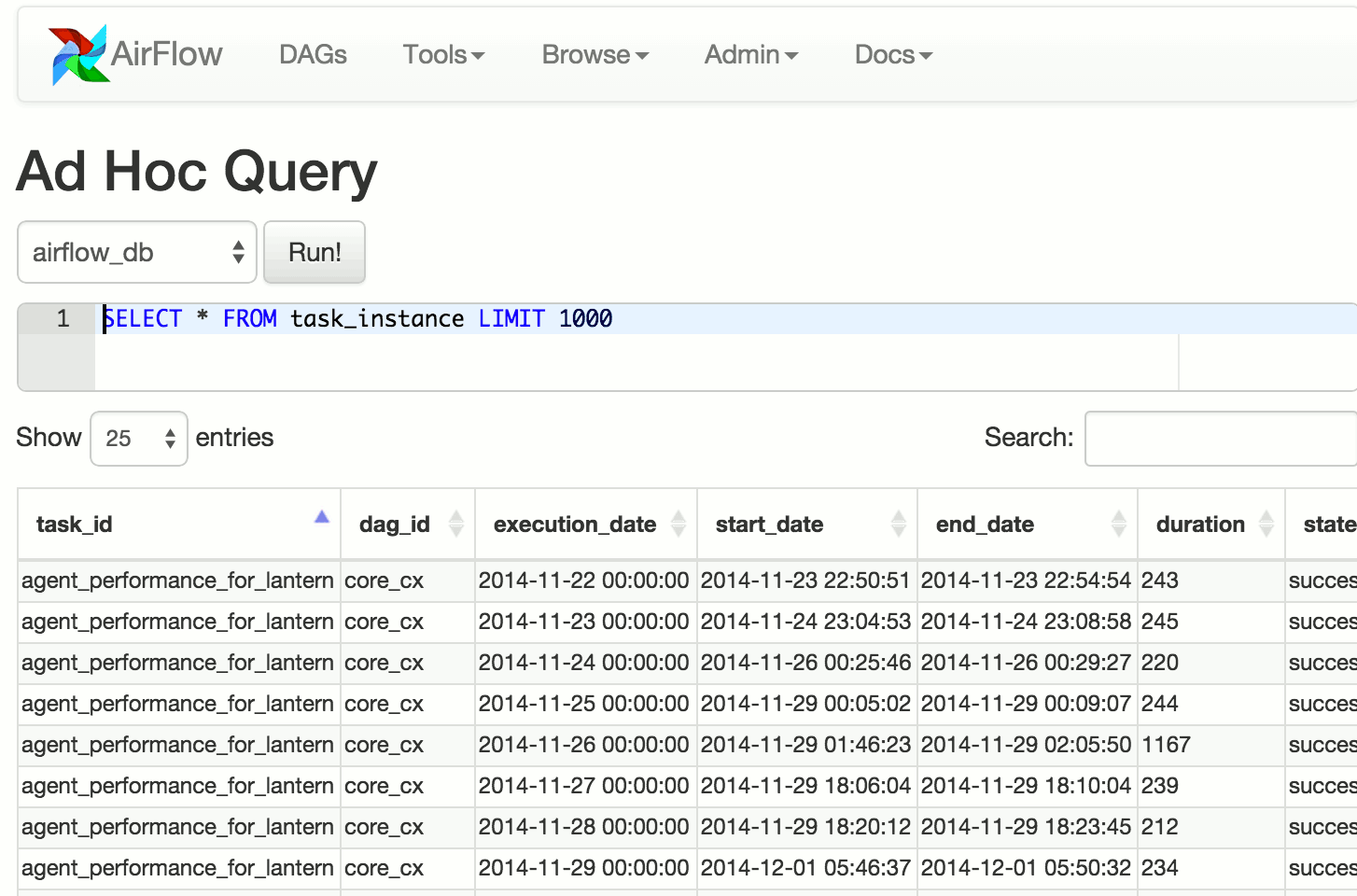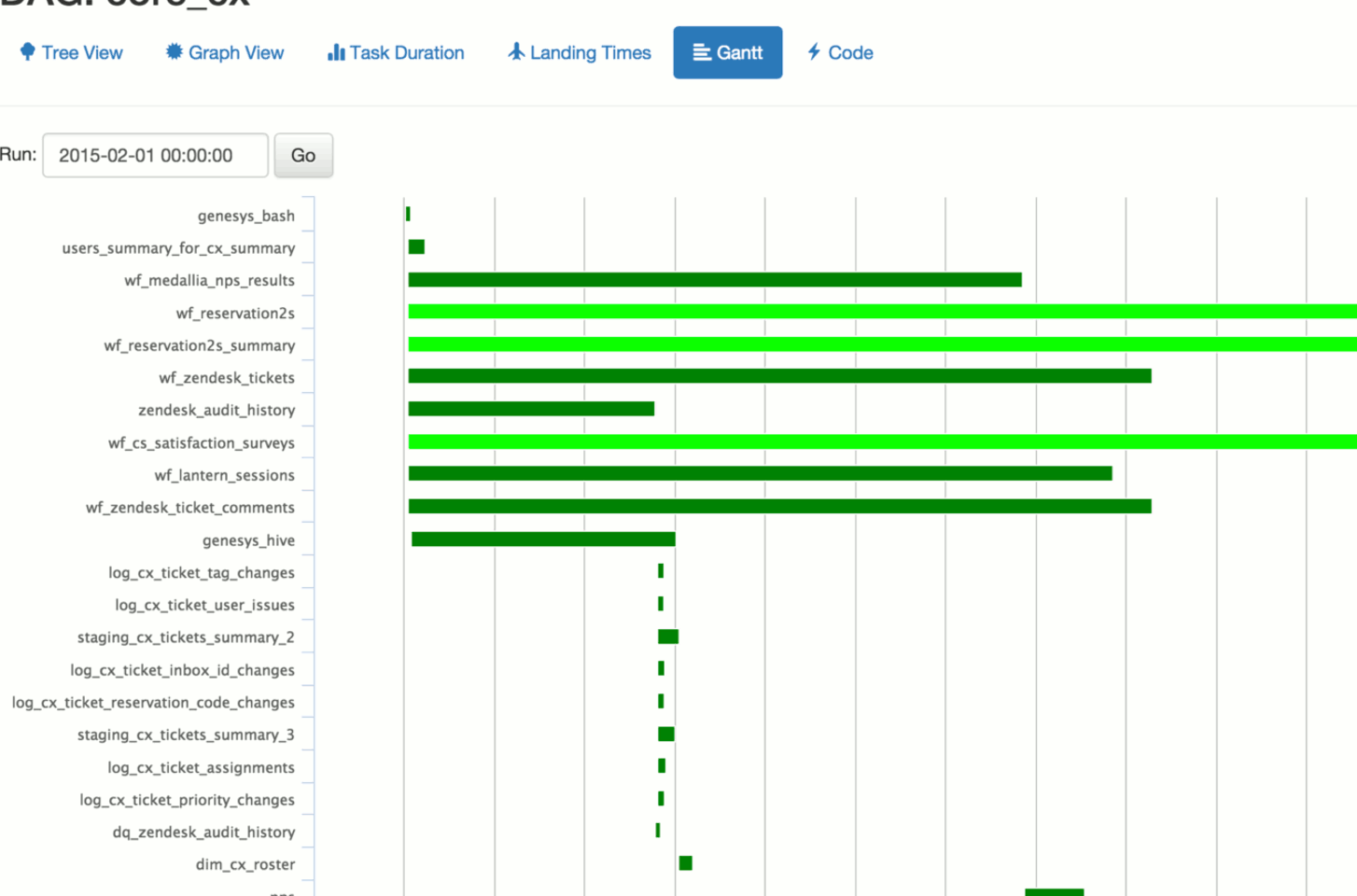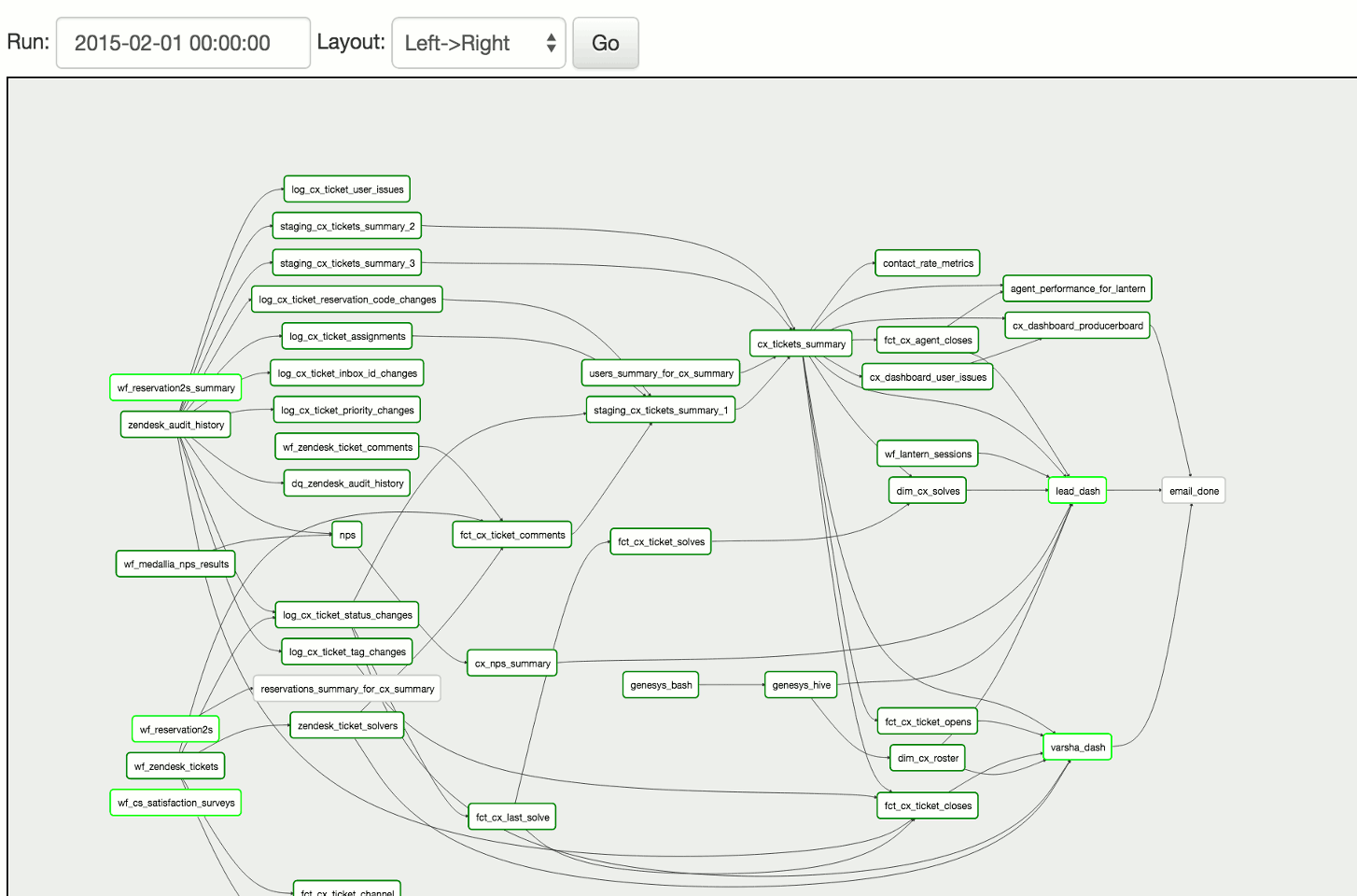
Les Concepts
L’utilisation d’Airflow se fait via du code Python. Mais avant cela voici quelques concepts qu’il vous faudra connaître afin de mettre les mains dans le cambouis.
DAG & Tasks
Airflow est principalement basé sur le concept de DAG, pour Directed Acyclic Graph. Un DAG n’est ni plus ni moins qu’un graphe orienté sans retour possible. Nos tâches s’exécuteront donc dans un ordre précis, en parallèle ou à la suite, et ce sans risque de boucle infinie.
![]()
Un DAG est constitué de tasks liées les unes aux autres. Vous avez déjà certainement entendu parlé de l’acronyme ETL pour Extract Transform Load, qui consiste à récupérer des données d’une source, à les transformer dans un nouveau format, puis à les renvoyer dans une seconde source adaptée à ce nouveau format.
Et bien Airflow s’adapte parfaitement bien à ce modèle. Voici un exemple de DAG contenant 3 tâches :
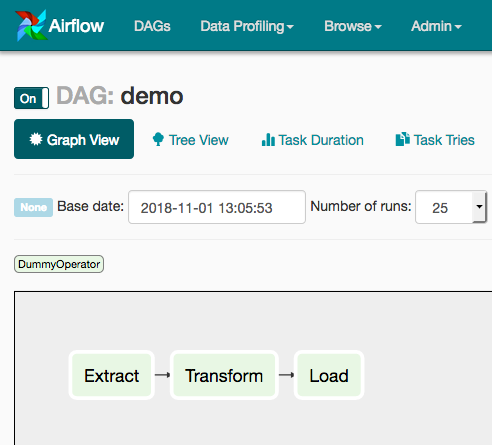
Un DAG est lancé de manière régulière ou via un trigger. Un DAG lancé ou en cours d’exécution est appelé une DagInstance, ses tâches étant donc des TaskInstances.
Operators
Les tâches d’un DAG ne sont pas toutes forcément du même type : nous aurons parfois besoin de lancer un script Bash, d’autres fois notre logique métier sera contenue dans une fonction Python, et parfois nous aurons simplement besoin d’envoyer un mail.
La création d’une tâche passe par des operators. A chaque besoin son operator :
BashOperator : exécute une commande bash,PythonOperator : exécute une fonction Python,EmailOperator : envoie un mail,DockerOperator : exécute une commande dans un container Docker,HttpOperator : effectue une requête sur un endpoint HTTP,- etc…
La liste des operators intégrés à Airflow est longue, et vous pouvez bien sûr créer les vôtres si besoin.
Pour l’aspect technique, un operator est tout simplement une classe Python héritant de BaseOperator. Lorsque la tâche est appelée, la fonction execute() de l’operator est exécutée. Vous l’aurez compris, un operator instancié devient donc une task.
Executors
Lorsqu’une tâche est appelée, elle va s’exécuter quelque part : ce quelque part est géré par Airflow via les executors.
Par défaut Airflow utilise le SequentialExecutor : les tâches sont lancées les unes après les autres sur le serveur local (là où Airflow lui-même est lancé) sans aucun parallélisme. Cet executor est pratique lorsqu’on développe, mais les limites sont vites atteintes lorsque l’on passe à l’échelle.
On pourra dans ce cas utiliser le LocalExecutor, plus performant que le précédent car basé sur un modèle prefork : plusieurs tâches pourront donc être lancées en parallèle jusqu’à ce que les ressources de la machine locale soient utilisées. Ici le scaling est vertical (plus de ressources signifie plus de tasks lancées en même temps).
Et le meilleur pour la fin : le CeleryExecutor. C’est via cet executor que le scaling des tâches pourra réellement se faire puisqu’Airflow ira déléguer à Celery la distribution des tâches sur un pool de workers. Le scaling sera donc horizontal : plus nous aurons de workers plus nous pourrons lancer de tâches en parallèle. Notons tout de même que Celery nécessite l’utilisation d’un broker pour l’échange des messages, ainsi qu’une synchronisation du code sur l’ensemble des workers (facilement réalisable avec l’utilisation de Redis & Kubernetes par exemple).
Création du DAG
Bon assez parlé, je me doute que vous avez envie de tester Airflow de ce pas. L’installation est commune à tous les packages Python :
$ pip install apache-airflow
Airflow va chercher les Dags dans le répertoire ~/airflow, mais nous pouvons changer ce comportement via la variable d’environnement AIRFLOW_HOME :
$ export AIRFLOW_HOME=~/Dev/python/demo_airflow
Une base de données est nécessaire pour faire fonctionner Airflow, nous la créons avec la CLI fournie lors de l’installation :
$ airflow initdb
$ ls
airflow.cfg airflow.db logs unittests.cfg
Plusieurs fichiers ont été créés, les plus importans étant les deux suivants :
airflow.db : il s’agit de la base de données utilisées par Airflow pour gérer nos Dags et leurs tasks. Ce fichier est au format SQLite3, on pourra le garder tout au long de nos développements mais je vous conseille fortement de passer sur un autre type (PostgreSQL ou MySQL par exemple) lors du passage en production.airflow.cfg : ce fichier contient la configuration d’Airflow, c’est ici par exemple que vous configurerez l’accès à la base de données, l’executor à utiliser, les paramètres de parallélisation, et j’en passe.
Créons maintenant notre DAG qui contiendra plus tard nos différentes tasks. La première étape consiste à instancier un object DAG et à lui fournir certains paramètres :
from datetime import datetime, timedelta
from airflow import DAG
default_args = {
'owner': 'ncrocfer',
'start_date': datetime(2018, 10, 31),
'retries': 5,
'retry_delay': timedelta(minutes=5)
}
dag = DAG('demo', default_args=default_args, schedule_interval='0 * * * *')
Les paramètres que nous déclarons dans la variable default_args sont assez parlants :
owner : l’utilisateur du DAG.start_date : Airflow lancera le DAG à partir de cette date.retries : le nombre d’essai qui sera effectué si une tâche tombe en erreur. Une fois cette valeur atteinte, le DAG tombera en erreur et sera stoppé.retry_delay : le temps d’attente entre deux essais.
Vous avez dû remarquer un pattern qui vous parle si vous utilisez les tâches cron : 0 * * * *. C’est en effet ici que l’on définit le cycle d’exécution du DAG, dans notre cas notre DAG demo sera exécuté chaque heure. La syntaxe est la même qu’avec les crontab, et certains raccourcis sont disponibles.
Vous devriez déjà voir votre DAG apparaître dans la liste :
$ airflow list_dags
[2018-11-01 16:35:35,220] {__init__.py:51} INFO - Using executor SequentialExecutor
[2018-11-01 16:35:35,564] {models.py:258} INFO - Filling up the DagBag from /Users/ncrocfer/Dev/python/demo_airflow/dags
-------------------------------------------------------------------
DAGS
-------------------------------------------------------------------
demo
Note : il se peut que d’autres DAG apparaissent dans votre liste. C’est en fait Airflow qui inclut des exemples de DAG. Vous pouvez les supprimer en passant à False la variable load_examples du fichier airflow.cfg, puis en remettant à zéro la base de données avec la commande airflow resetdb.
Création des Tâches
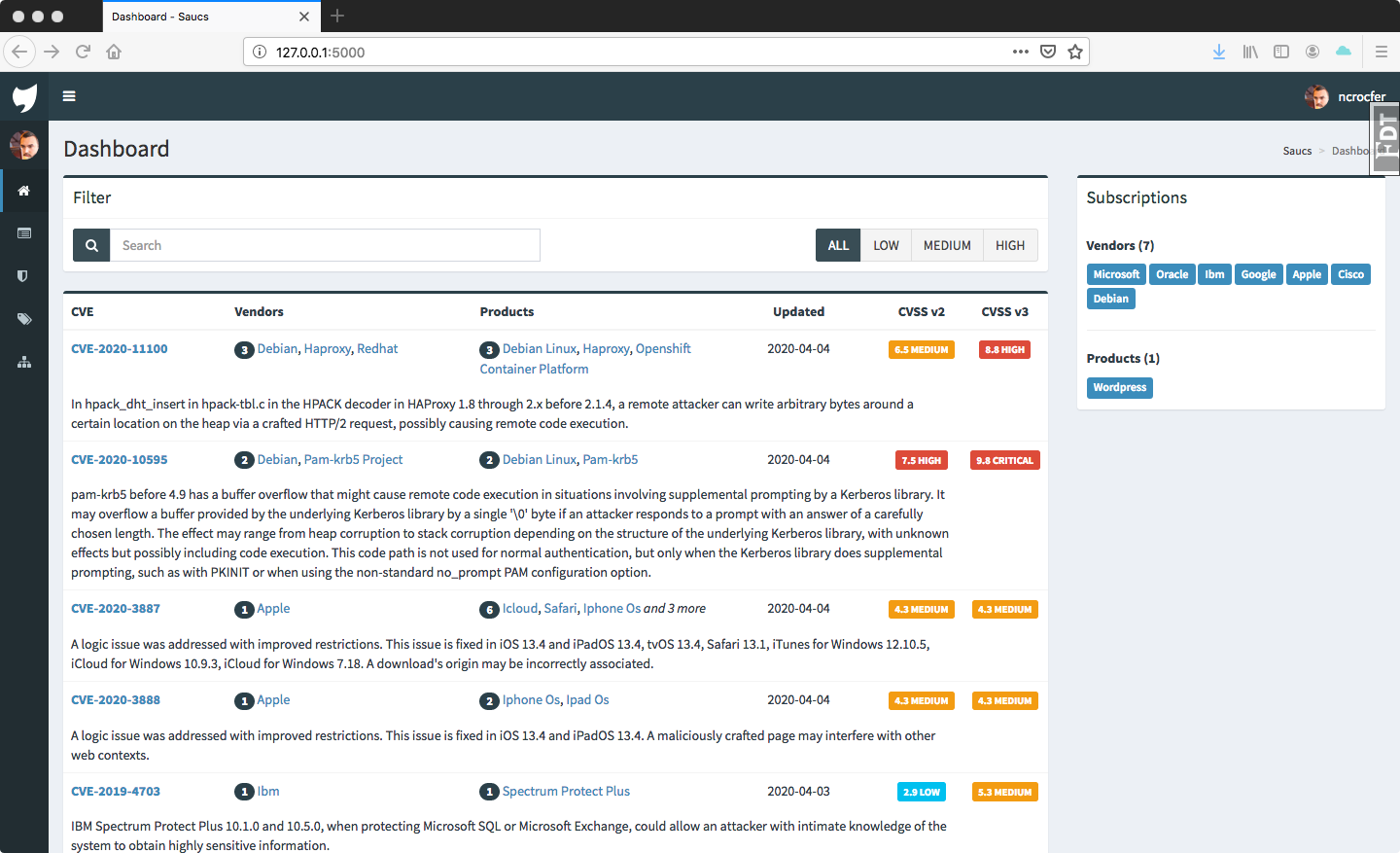
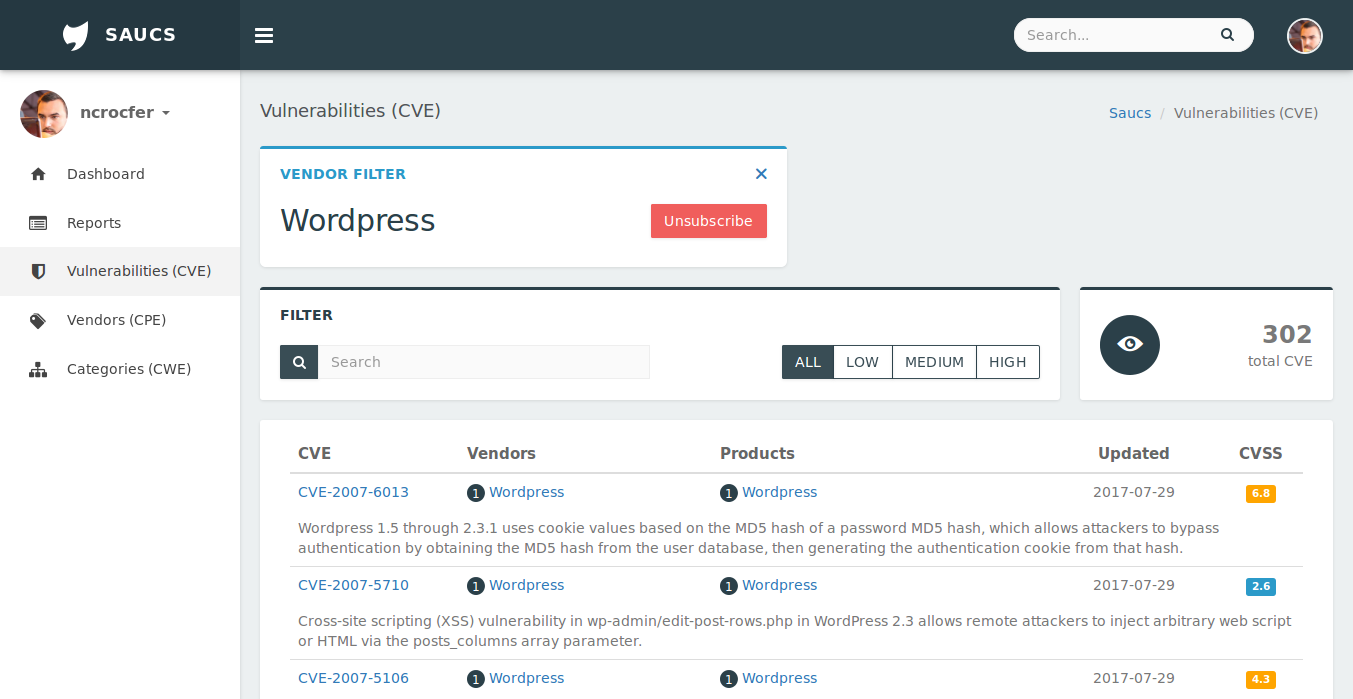
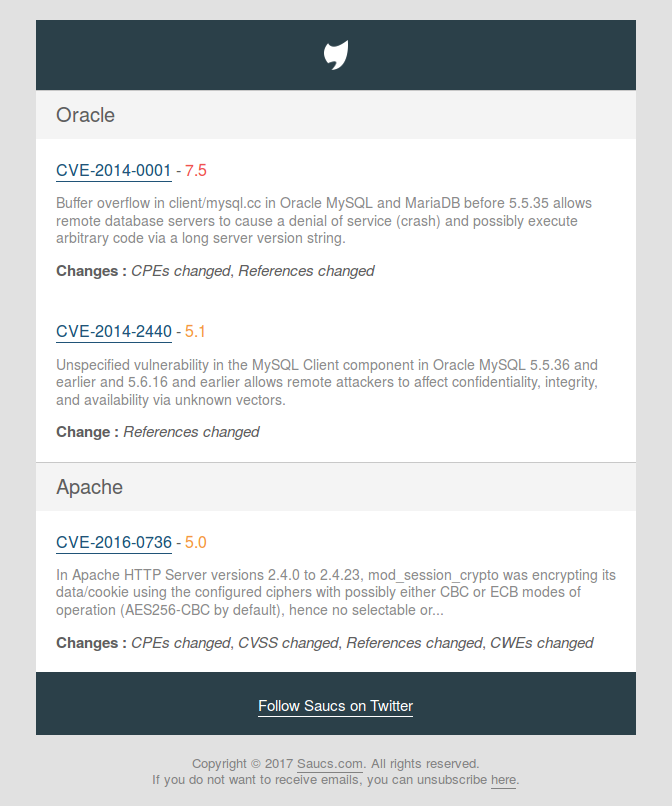
Nous devons maintenant créer nos tâches. Je vais prendre comme exemple le site Saucs.com, pour lequel je gère la partie développement. Pour rappel ce site permet aux utilisateurs de s’abonner à des produits et de recevoir un rapport par mail dès qu’une vulnérabilité apparaît sur le site du NVD.
L’ordre des tâches est donc le suivant :
CheckUpdates : On vérifie sur le site du NVD si une mise à jour des CVE a eu lieu,DownloadXml : On télécharge les nouvelles CVE,ParseXml : On parse les nouvelles CVE et on met à jour notre base de données,SendMails : On envoie un mail aux utilisateurs abonnés aux produits impactés.
Comme expliqué plus haut, la création de tâches se fait via l’utilisation des operators. Nous allons pour cet exemple utiliser plusieurs PythonOperator auxquels nous passons des fonctions Python :
Voici le code final de notre DAG :
import gzip
import logging
import re
from datetime import datetime, timedelta
from io import BytesIO
from xml.etree import ElementTree as ET
import requests
from airflow import DAG
from airflow.operators.python_operator import BranchPythonOperator, PythonOperator
default_args = {
'owner': 'ncrocfer',
'start_date': datetime(2018, 10, 31),
'retries': 5,
'retry_delay': timedelta(minutes=5)
}
logger = logging.getLogger(__name__)
NVD_MODIFIED_META_URL = 'https://static.nvd.nist.gov/feeds/xml/cve/2.0/nvdcve-2.0-Modified.meta'
NVD_MODIFIED_URL = 'https://static.nvd.nist.gov/feeds/xml/cve/nvdcve-2.0-Modified.xml.gz'
LAST_NVD_HASH = '/tmp/lastnvd'
def check_updates():
logger.info("Downloading {url}...".format(url=NVD_MODIFIED_META_URL))
resp = requests.get(NVD_MODIFIED_META_URL)
buf = BytesIO(resp.content).read().decode('utf-8')
nvd_sha256 = buf.split('sha256')[1][1:-2]
logger.info("New NVD hash is : {hash}".format(hash=nvd_sha256))
try:
with open(LAST_NVD_HASH) as f:
last_nvd256 = f.read()
except FileNotFoundError:
last_nvd256 = None
logger.info("Local hash is : {hash}".format(hash=last_nvd256))
if nvd_sha256 != last_nvd256:
logger.info("Hashes differ, Saucs database needs to be updated...")
return {'updated': True, 'hash': nvd_sha256}
else:
logger.info("Hashes are the same, nothing to do.")
return {'updated': False}
def download_xml(ds, **context):
update = context['task_instance'].xcom_pull(task_ids='CheckUpdates')
if not update['updated']:
return
logger.info("Downloading {url}...".format(url=NVD_MODIFIED_URL))
resp = requests.get(NVD_MODIFIED_URL)
buf = BytesIO(resp.content)
data = gzip.GzipFile(fileobj=buf)
xml_string = data.read().decode('utf-8')
xml_string = re.sub(' xmlns="[^"]+"', '', xml_string)
with open('/tmp/{0}.xml'.format(ds), 'w') as f:
f.write(xml_string)
def parse_xml(ds, **context):
update = context['task_instance'].xcom_pull(task_ids='CheckUpdates')
if not update['updated']:
return
parser = ET.XMLParser(encoding="utf-8")
tree = ET.parse('/tmp/{0}.xml'.format(ds), parser=parser)
root = tree.getroot()
for child in root:
logger.info("Parsing {cve}...".format(cve=child.attrib.get('id')))
# 1. Process the CVE (new CVE, CPE updated, references updated, CVSS updated...)
# 2. Create an alert for all impacted users
def send_mails(ds, **context):
update = context['task_instance'].xcom_pull(task_ids='CheckUpdates')
if not update['updated']:
return
logger.info('Sending mail for users with an alert')
"""users = get_users_with_alerts()
for user in users:
send_user_mail()
user.new_alerts = False"""
# We're done, we can set the new NVD hash in local
with open(LAST_NVD_HASH, 'w') as f:
f.write(update['hash'])
dag = DAG('demo', default_args=default_args, schedule_interval='0 * * * *')
with dag:
check_updates_op = PythonOperator(
task_id='CheckUpdates',
python_callable=check_updates
)
download_xml_op = PythonOperator(
task_id='DownloadXml',
provide_context=True,
python_callable=download_xml
)
parse_xml_op = PythonOperator(
task_id='ParseXml',
provide_context=True,
python_callable=parse_xml
)
send_mails_op = PythonOperator(
task_id='SendMails',
provide_context=True,
python_callable=send_mails
)
# Order the tasks
check_updates_op >> download_xml_op >> parse_xml_op >> send_mails_op
"""
# Can be written :
check_updates_op.set_downstream(download_xml_op)
download_xml_op.set_downstream(parse_xml_op)
parse_xml_op.set_downstream(send_mails_op)
"""
La logique des 4 fonctions n’est pas compliquée et ne concerne pas directement Airflow, je ne m’étalerai pas dessus. En revanche certaines parties du code sont nouvelles :
- On constate l’ouverture d’un context manager (
with dag) juste après la déclaration du DAG : cela signifie que tous les opérateurs déclarés à l’intérieur de celui-ci seront liés à notre DAG.
- Certains opérateurs possèdent le paramètre
provide_context : dans ce cas les fonctions à lancer (renseignées via le paramètre python_callable) recevront les paramètres ds et context. Le premier est un string représentant la date d’éxecution de la tâche, le second est un dictionnaire contenant des informations relatives à l’instance de tâche.
- Nous utilisons les xcom : il s’agit d’une fonctionnalité proposée par Airflow afin de communiquer des informations d’une tâche à une autre.
- la dernière ligne peut paraître obscure : il s’agit en fait tout simplement de la façon dont nous déclarons l’ordre de lancement de nos tâches. Nous utilisons ici les opérateurs bits à bits (Bitwise operators) car je trouve que la forme est assez parlante, mais Airflow propose également les méthodes
set_upstream() et set_downstream().
Nous pouvons tester que tout fonctionne correctement grâce à la commande list_tasks :
$ airflow list_tasks demo --tree
2018-11-01 18:45:03,572] {__init__.py:51} INFO - Using executor SequentialExecutor
[2018-11-01 18:45:03,785] {models.py:258} INFO - Filling up the DagBag from /Users/ncrocfer/Dev/python/demo_airflow/dags
<Task(PythonOperator): SendMails>
<Task(PythonOperator): ParseXml>
<Task(PythonOperator): DownloadXml>
<Task(PythonOperator): CheckUpdates>
Exécution du DAG
Tout semble en ordre, nous pouvons lancer le serveur web :
$ airflow webserver
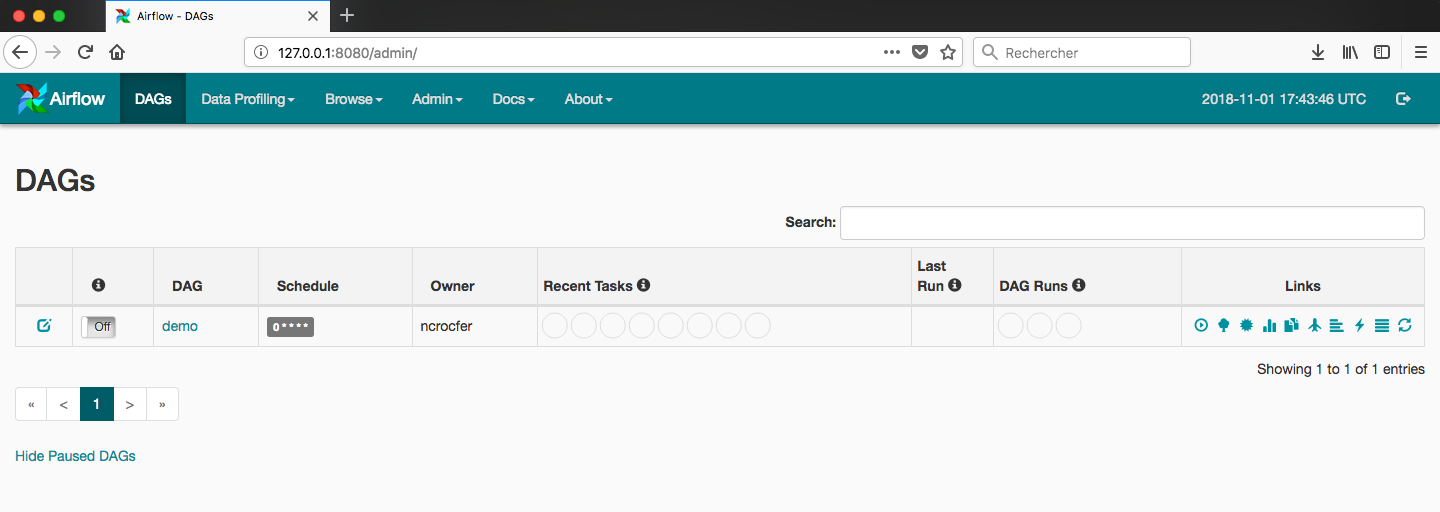
Par défaut l’interface est disponible en localhost sur le port 8080. Nous pouvons y voir notre DAG :
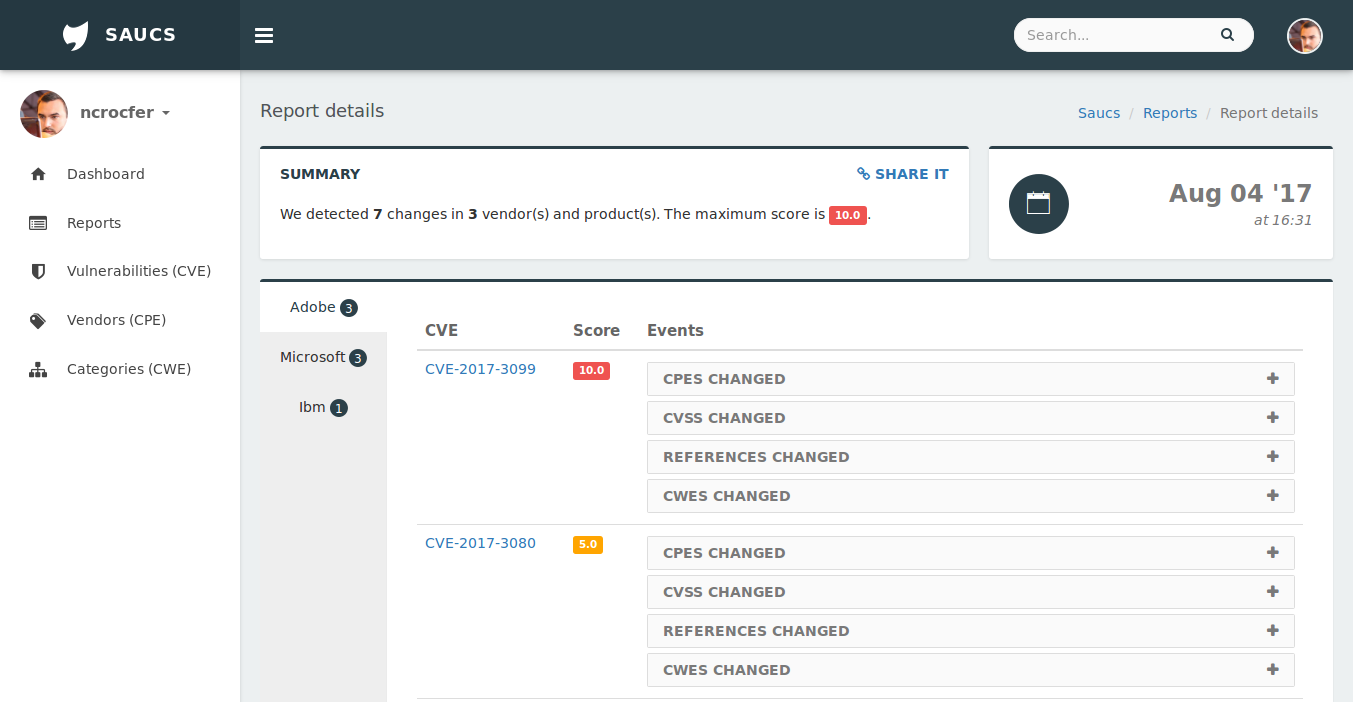
L’exécution du DAG nécessite deux actions :
- tout d’abord il faut l’activer (le bouton On/Off),
- puis vous devez lancer le scheduler d’Airflow.
C’est ce dernier qui va gérer pour nous l’ordonnancement des tâches, leur retry si besoin, et c’est également lui qui vérifiera en permanence si un nouveau DagRun ne doit pas être lancé :
$ airflow scheduler
Cliquez maintenant sur le DAG demo, puis sur l’onglet Graph View. Le DAG a bien été lancé :
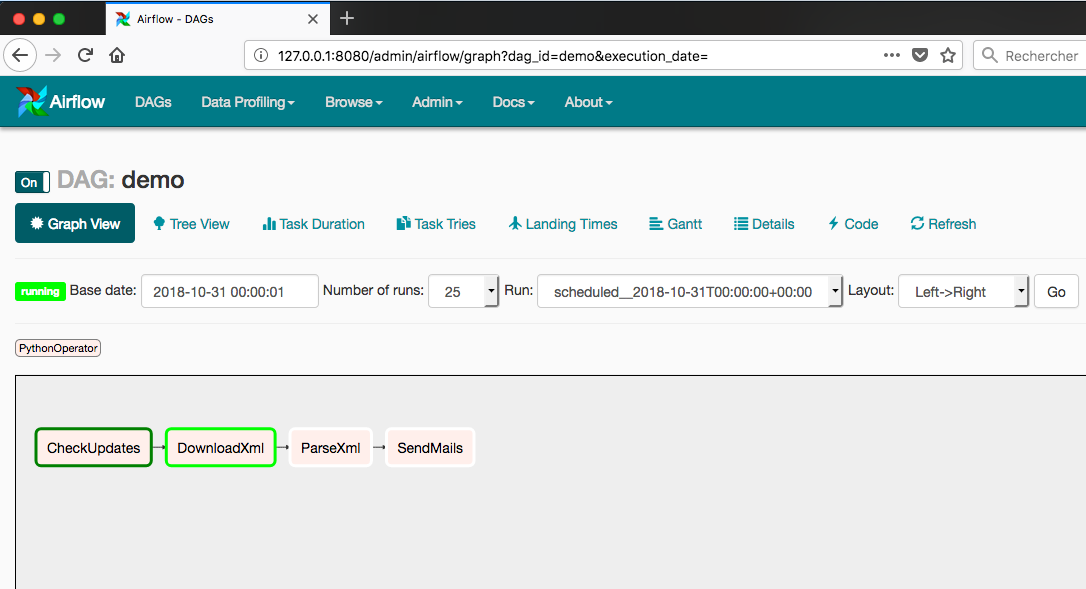
Airflow s’occupe désormais de tout et va lancer le DAG chaque heure, et ce depuis le start_date (le scheduler effectue ce qu’on appelle le backfill, ce comportement étant modifiable grâce à la configuration catchup_by_default ou au paramètre catchup du DAG lui-même) :
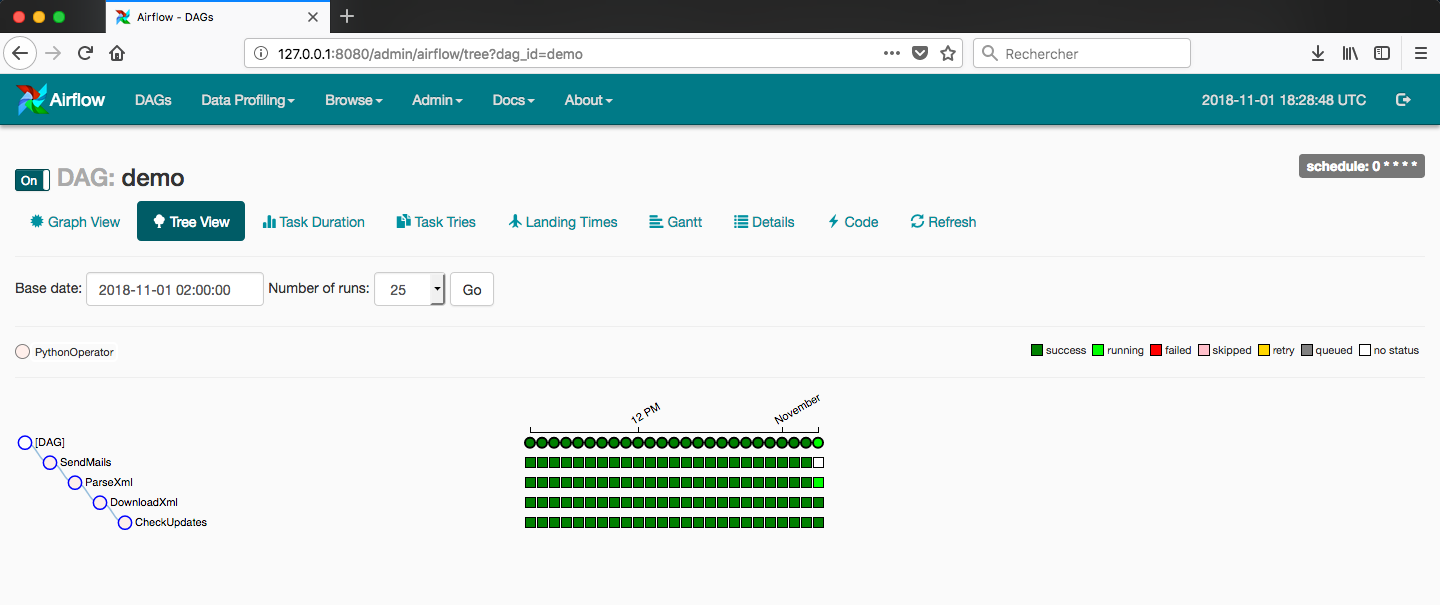
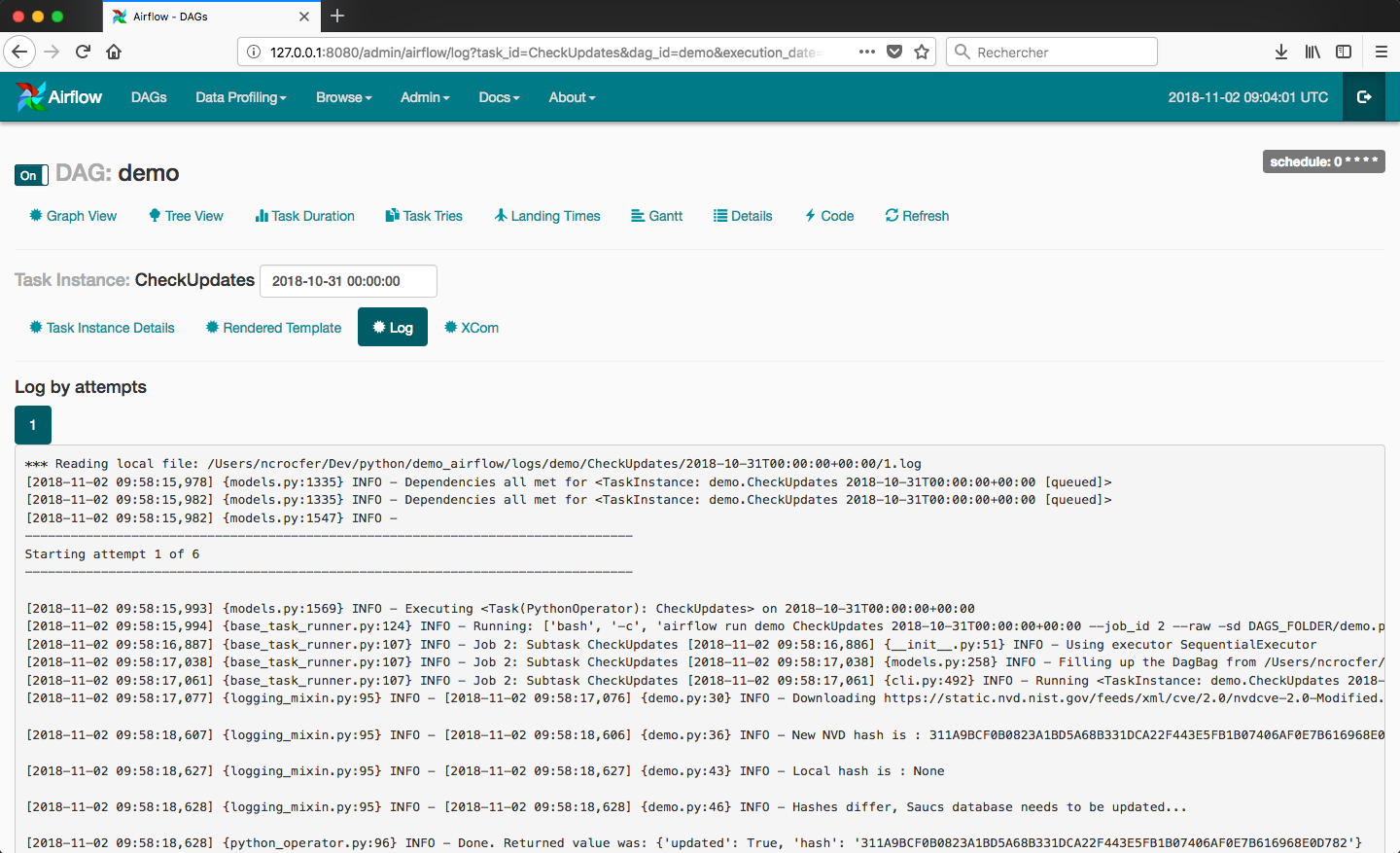
Pour finir il est important de noter que le monitoring de nos tâches est très simple puisqu’Airflow fournit une interface pour visualiser les logs (et donc potentiellement les exceptions lancées).
Vous pouvez voir les logs d’une tâche en cliquant sur la tâche puis sur le bouton View Log :
Conclusion
Je m’arrête ici pour cette présentation d’Apache Airflow. Il y a beaucoup de chose à dire dessus, nous n’avons fait qu’effleurer le sujet mais j’espère néanmoins vous avoir donner envie de le tester.
L’exemple que j’ai donné était très simple : j’ai volontairement épuré le Dag de Saucs afin de vous montrer un exemple concret d’usage d’Airflow sans polluer le code par de la logique externe au tool. De même vous aurez peut-être remarqué que chaque tâche est exécutée même si aucune mise à jour n’a été effectuée par le NVD. La solution dans ce cas aurait été d’utiliser l’opérateur BranchPythonOperator afin de renvoyer vers la tâche adéquate, mais cela aurait compliqué cet article et ce n’était pas l’objectif souhaité.
Airflow est un outil que j’utilise désormais au quotidien, et je ne peux que vous conseiller de l’essayer vous-aussi. Je tenterai dans les prochains articles de couvrir d’autres fonctionnalités d’Airflow, tels que les BranchOperator, le CeleryExecutor ou encore la création dynamique de Dags.