Je travaille depuis un an et demi sur un projet chez OVH qui calcule la qualité de service de notre infrastructure.
Cet outil, nommé DEPC, se compose d’une API développée en Flask ainsi que d’une WebUI. Le fonctionnement interne repose sur 3 composants majeurs :
- Apache Airflow pour le scheduling,
- les base de données TimeSeries pour le calcul de la QOS,
- et enfin la base de données Neo4j pour la gestion des dépendances.
Je ne vais pas présenter DEPC dans cet article, nous allons bientôt l’open sourcer et j’en parlerai à ce moment-là. En revanche laissez-moi vous présenter une base données que j’utilise désormais au quotidien et que j’affectionne tout particulièrement : Neo4j.
![]()
Base de données orientée graphe
En tant que développeur nous sommes habitués à travailler avec des bases de données relationnelles, que ce soit PostgreSQL, MySQL ou encore Oracle pour n’en citer que quelques unes (la liste est longue).
Pour rappel l’élément principal d’une base de données relationnelle est la table : les données qui y sont stockées sont organisées sous forme de tableau où chaque ligne correspond à un enregistrement et chaque colonne à une catégorie de même type.
Ce format est parfait pour la plupart de nos usages, notamment grâce à leur propriété ACID. Néanmoins les limites sont vite atteintes dans certains cas, notamment lorsqu’il s’agit de réaliser plusieurs jointures en une seule requête.
Les bases de données orientées graphe ont donc été créées pour pallier entre autres à ce problème. Et on peut dire qu’elles connaissent un succès grandissant depuis quelques années (source):
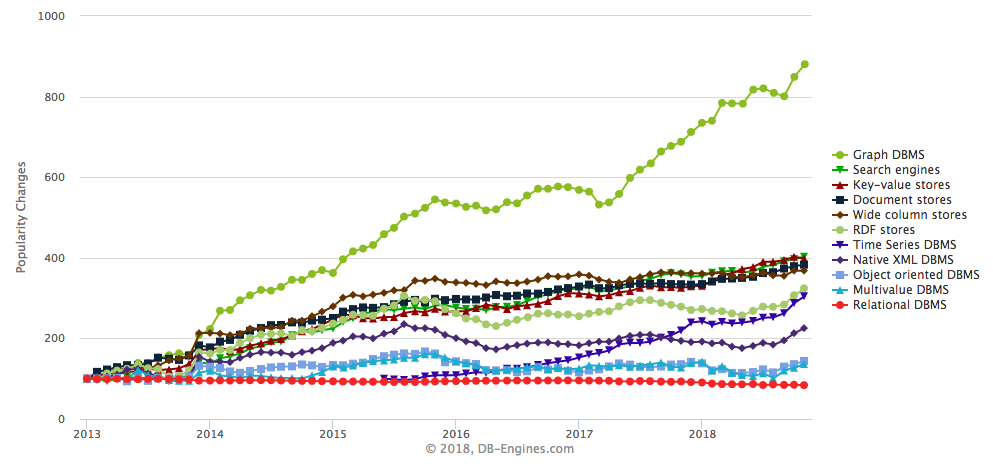
Et ça tombe bien puisque Neo4j est la base de données orientées graphe la plus répandue !
Intérêts des graphes
Un graphe représente un ensemble de points reliés entre eux par des arcs (source de l’image):

L’intérêt des graphes devient évident lorsque l’on souhaite visualiser les intéractions entre différentes données.
Prenons le cas d’un projet Python nécessitant de nombreuses librairies. Certaines de ces librairies nécessitent elles-même d’autres librairies, et ainsi de suite. Il est très difficile avec pip de retrouver qui dépend de qui.
Le projet Scrapy par exemple requiert une vingtaine de librairies :
$ pip install scrapy
$ pip freeze | wc -l
25
Vous le savez la sortie de pip freeze nous renvoie la liste des modules à plat, sans aucune arborescence. Il est alors très difficile de visualiser quelle librairie dépend d’une autre.
Nous pouvons utiliser l’outil pipdeptree afin de générer un arbre de dépendances de nos modules :
$ pip install pipdeptree graphviz
$ pipdeptree --graph-output png > scrapy.png
Nous obtenons le graphe suivant, bien plus lisible que le résultat de pip :
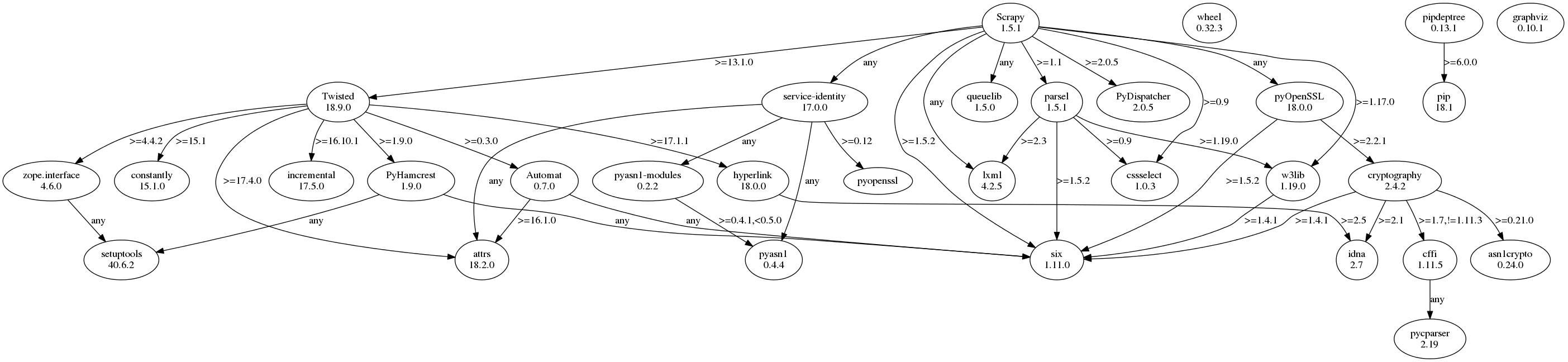
Comme vous le voyez les graphes permettent très rapidement de comprendre la structure de la base de données et les relations entre les différents noeuds. Le graphe précédent nous permet facilement de distinguer quelles sont les dépendances directes et indirectes de Scrapy.
Ce graphe ne contient que quelques dizaines de noeuds, nous pouvons donc facilement le parcourir de tête. Mais imaginez un graphe contenant plusieurs centaines de milliers de noeuds liés entre eux par des relations.
Et bien Neo4j répond à cette problématique en nous fournissant les outils nécessaires à la construction et au parcours optimisé de nos graphes !
Les concepts
Les données stockées dans Neo4j vont donc être organisées sous la forme d’un graphe, les noeuds étant reliés entre eux par des relations. Des propriétés (clé:valeur) peuvent enrichir les noeuds et les relations afin d’y ajouter du contexte :
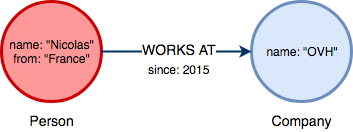
Nous pouvons retrouver 2 noeuds dans ce graphe reliés entre eux par une relation de type WORKS AT. Des propriétés ont été ajoutées afin de compléter les informations propres à chaque noeud.
Des noeuds de même type sont regroupés au sein de labels :
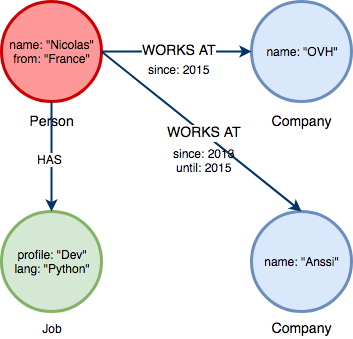
Nous avons rajouté un noeud de label Job, lié au noeud Person via une relation de type HAS. Sur ce graphe nous pourrions très facilement répondre à la requête “Donnes moi l’emploi actuel de tous les développeurs Python Français”.
Et c’est tout ! Il existe évidemment d’autres notions internes à Neo4j, telles que les index ou les contraintes, mais ces 4 notions de base (noeuds, relations, propriétés, labels) suffisent à débuter l’utilisation concrète de Neo4j !
Installation
Neo4j s’installe très simplement dès lors que Java 8 est disponible sur votre OS. Je suis pour ma part sur Debian, nous devons donc ajouter le repo officiel à nos sources :
$ wget -O - https://debian.neo4j.org/neotechnology.gpg.key | sudo apt-key add -
$ echo 'deb https://debian.neo4j.org/repo stable/' | sudo tee -a /etc/apt/sources.list.d/neo4j.list
$ sudo apt-get update
Puis nous installons ensuite Neo4j comme tous les autres packages (la dernière version stable à l’écriture de cet article est la 3.5.0) :
$ sudo apt-get install neo4j=1:3.5.0
Utilisation
La première chose à faire est d’ouvrir le Neo4j Browser : il s’agit d’une application très pratique qui va vous permettre de créer vos données et de les visualiser à travers une interface web.
Le browser est accessible en local sur le port 7474 : http://localhost:7474.
Vous devez tout d’abord vous connecter grâce aux identifiants neo4j / neo4j (pas d’inquiétude le browser vous demandera tout de suite après de modifier votre mot de passe).
Voici ce que vous devriez obtenir une fois connecté :
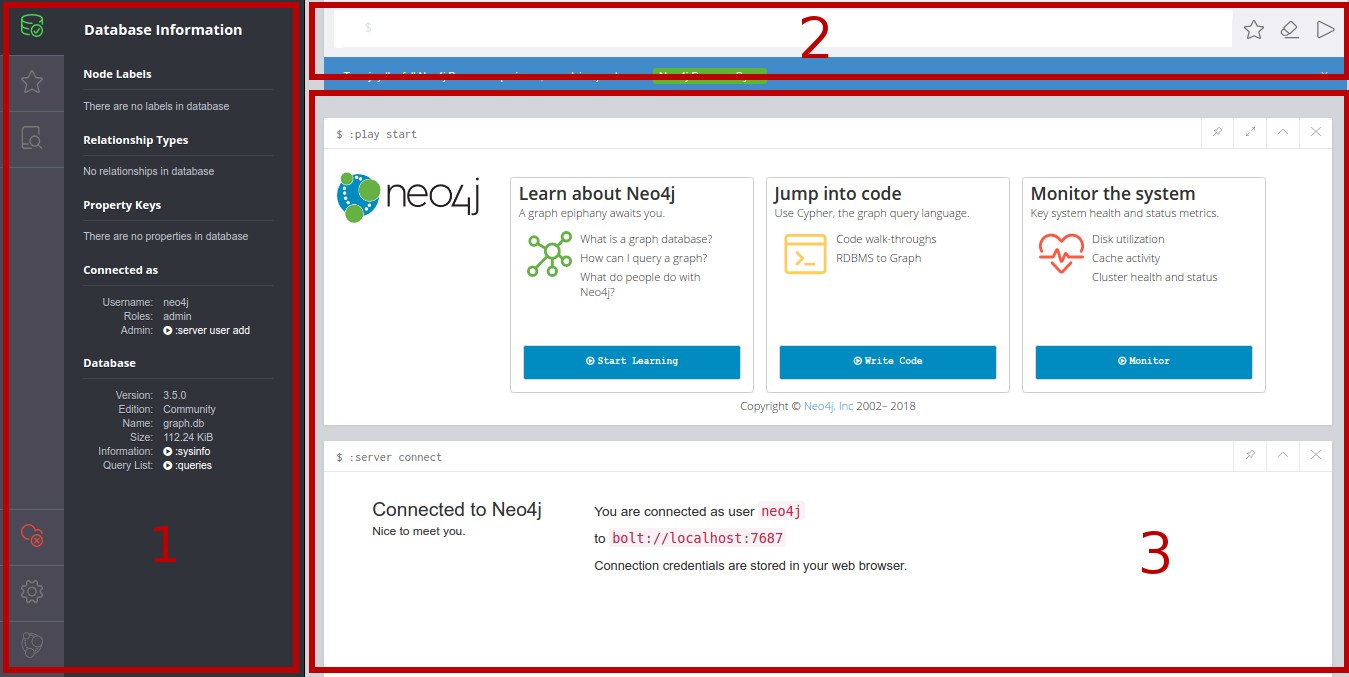
Comme vous le voyez le browser peut se découper en 3 parties :
- C’est ici que nous retrouverons des informations sur notre instance Neo4j, comme la version ou la taille, ainsi que la liste des labels, des types de relations et des propriétés stockées dans notre base de données.
- Ce formulaire va vous permettre de saisir vos requêtes afin d’interroger Neo4j.
- Et c’est dans cette vue que les résultats de vos précédentes requêtes s’afficheront.
Nous allons créer les 4 noeuds que j’ai donné en exemple dans la partie “Les concepts”. Pour cela nous allons utilisons un langage de requête créé pour Neo4j : le Cypher, qui est un peu le SQL des graphes :)
Par exemple l’insertion et la sélection d’une données en SQL se ferait grâce à la requête suivante :
CREATE TABLE person (name varchar, from varchar);
INSERT INTO person VALUES ('Nicolas', 'France');
SELECT * FROM person;
Voici l’équivalent en Cypher :
CREATE(nico:Person{name: "Nicolas", from: "France"}) RETURN nico;
Vous pouvez remarquer plusieurs choses :
- la création d’un noeud se fait grâce au mot-clé
CREATE, - le noeud (que nous avons nommé
nico) est entouré de parenthèses, - les propriétés s’ajoutent entre les accolades,
- nous retournons le noeud nouvellement créé.
Notez également que nous n’avons pas eu besoin de créer le label Person. En effet Neo4j s’est chargé de le faire lui-même au moment de la création du noeud (pour rappel Neo4j fait partie des bases de données NoSQL).
Nous pouvons d’ailleurs le voir dans le Browser Neo4j sous la partie “Node Labels” :
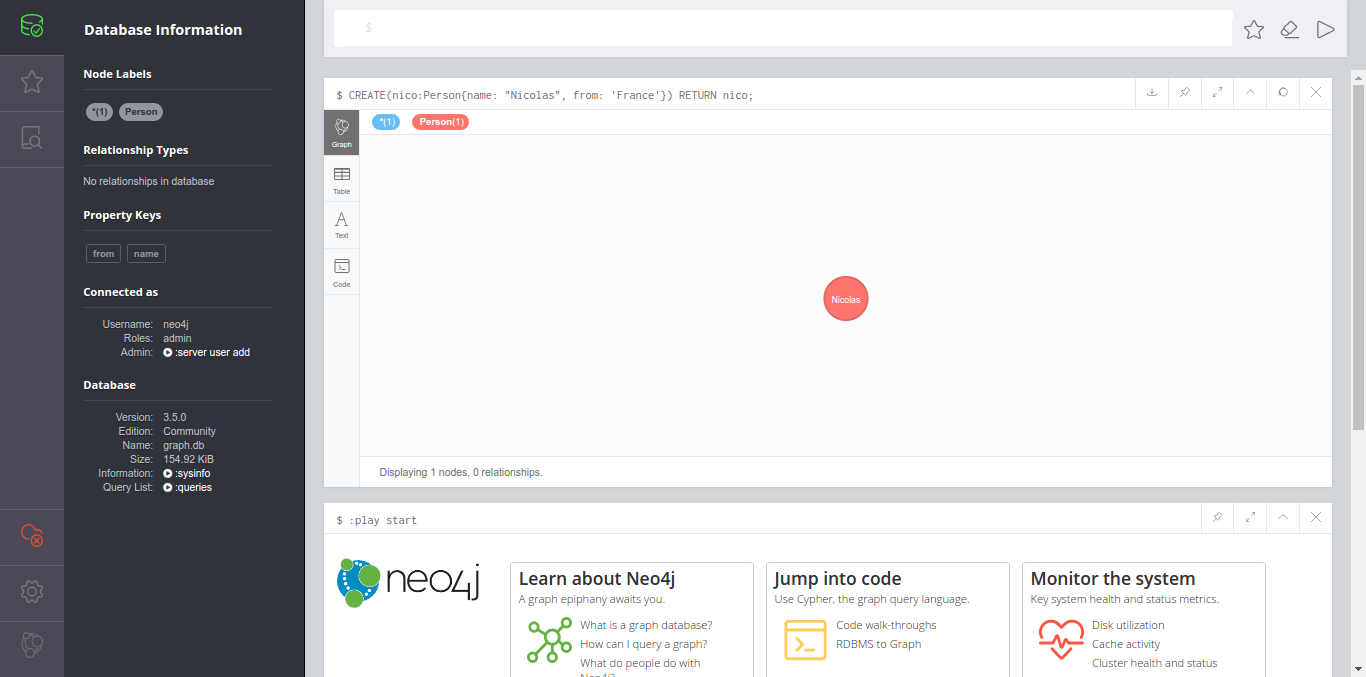
Nous allons maintenant créer le noeud de type Job que nous lierons avec le noeud Person grâce à la requête suivante :
MATCH(nico:Person{name: "Nicolas", from: "France"})
CREATE(nico)-[:HAS]->(job:Job{profile: "Dev", lang: "Python"})
RETURN nico, job;
La forme change un peu ici :
- tout d’abord je sélectionne le noeud
nico, - puis, en utilisant une seule requête CREATE, je créé en base le noeud
jobet j’ajoute la relationHASentre les deux, - je retourne pour finir mes 2 noeuds.
Les propriétés peuvent être visibles dans le Browser en survolant un noeud :
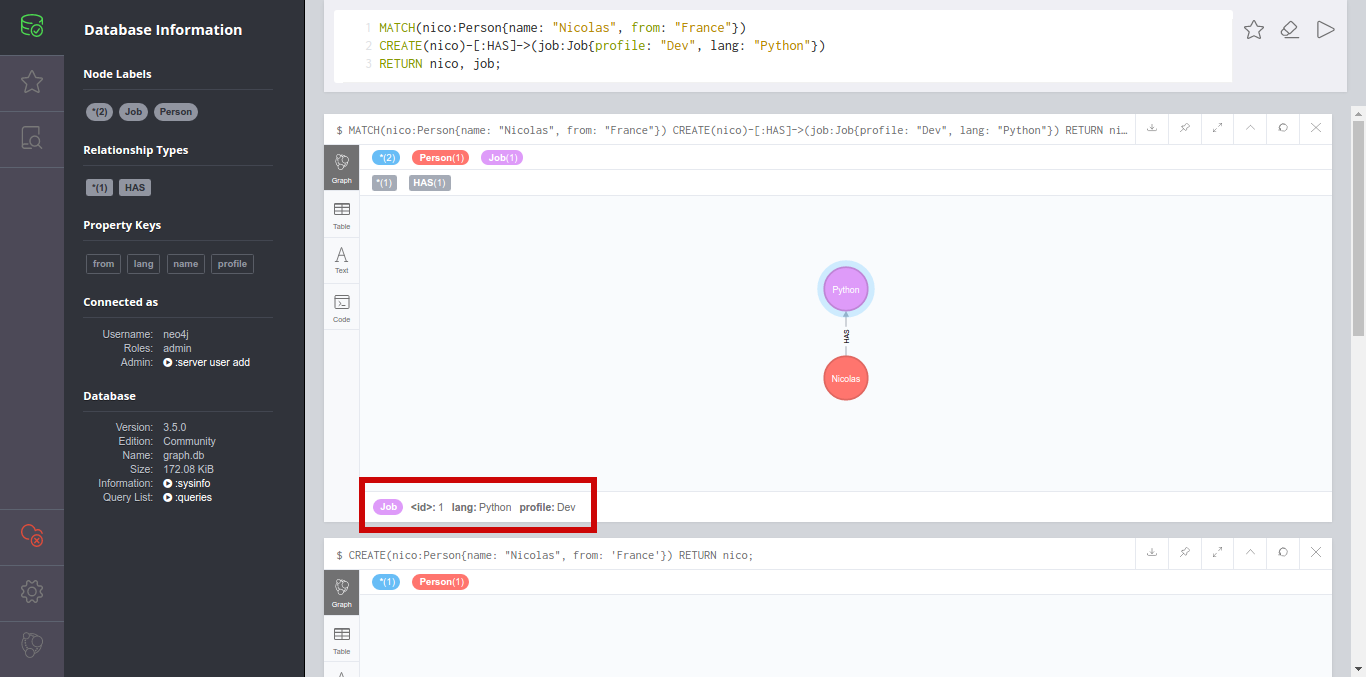
Pour finir créons en une seule requête les noeuds de type Company :
MATCH(nico:Person{name: "Nicolas", from: "France"})
MERGE(nico)-[:`WORKS AT`{since: 2015}]->(ovh:Company{name: "OVH"})
MERGE(nico)-[:`WORKS AT`{until: 2015, since: 2013}]->(anssi:Company{name: "Anssi"})
RETURN nico, ovh, anssi;
Note : Les plus attentifs auront remarqué le mot-clé MERGE, que nous pourrions renommer en GET or CREATE. Il agit ici comme le CREATE que nous avons vu plus tôt, mais cette commande n’aurait rien ajouté de plus si les noeuds Company et leurs relations existaient déjà. Je vous la montre car elle peut être très pratique lorsque l’on souhaite réaliser des requêtes idempotentes.
Il est désormais temps d’afficher notre graphe, et le browser va nous être très pratique car nous allons le faire sans écrire une seule requête :
- Sélectionnez le label
Persondans la liste des labels à gauche de l’écran. - Vous devriez voir apparaître le noeud “Nicolas”, cliquez dessus.
- Le noeud s’entoure alors de différent bouton, cliquez sur celui du bas afin de déplier les dépendances directes.
Nous avons bien affiché le graphe complet sans taper une ligne de Cypher :
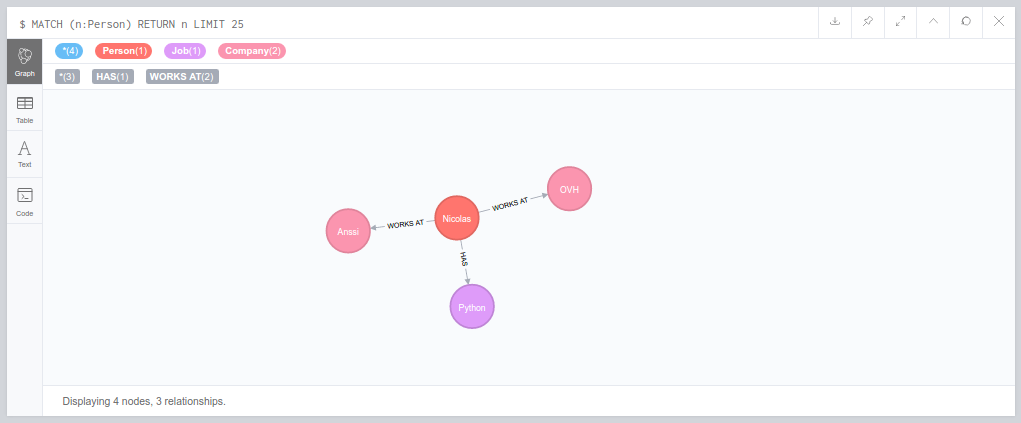
Pour info la requête équivalente aurait été la suivante :
MATCH(n:Person)-[]->(m) RETURN n, m
L’astuce consiste à sélectionner les noeuds de type Person, puis à retourner l’ensemble de ses dépendances sans rien filtrer. Attention néanmoins à cette requête si votre graphe contient trop de données, votre navigateur risque de ne pas apprécier :)
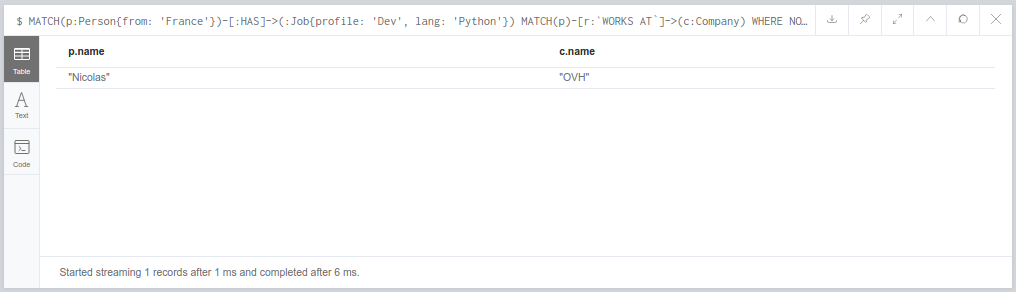
Pour finir cette partie souvenez-vous de la question posée plus haut : “Donnes moi l’emploi actuel de tous les développeurs Python Français”. Et bien la réponse serait apportée par la requête suivante :
MATCH(p:Person{from: 'France'})-[:HAS]->(:Job{profile: 'Dev', lang: 'Python'})
MATCH(p)-[r:`WORKS AT`]->(c:Company)
WHERE NOT EXISTS(r.until)
RETURN p.name, c.name
Conclusion
Nous n’avons fait que survoler Neo4j et le Cypher. Si vous souhaitez en apprendre plus sur ce langage, je vous invite à vous tourner vers la documentation officielle, vous y apprendrez notamment à filtrer vos résultats, à les ordonner ou encore à utiliser des algorithmes optimisés de parcours de graphe.
Comme je le disais en introduction de cet article j’utilise désormais Neo4j au quotidien dans le cadre de DEPC. Nous gérons plusieurs millions de noeuds et autant de relations, et je dois dire que je ne suis pas du tout déçu de ce choix technique.
Evidemment le choix d’une base de données orientée graphe répondra généralement à une problématique précise. Bien souvent une base de données relationnelle répondra à vos besoins, mais si vos données peuvent s’architecturer sous la forme d’un graphe alors n’hésitez pas et sautez le pas, vous ne serez pas déçu.