Je travaille en ce moment sur l’opensource de Saucs (qui va d’ailleurs être renommé, j’en parlerai plus tard) et notamment sur la partie performance des requêtes SQL.
Si vous ne connaissez pas Saucs il s’agit d’un outil permettant de s’abonner à des vendeurs et leurs produits puis d’être notifié en cas de nouvelle CVE (ou de mise à jour d’une ancienne).
Sans JSONB
Voici le schema actuel :
$ \dt
List of relations
Schema | Name | Type | Owner
--------+-----------------+-------+----------
…
public | products | table | ncrocfer
public | products_cves | table | ncrocfer
public | users | table | ncrocfer
public | users_products | table | ncrocfer
public | users_vendors | table | ncrocfer
public | vendors | table | ncrocfer
public | vendors_cves | table | ncrocfer
Une table par vendors et products, puis des tables d’associations avec les CVES. De même nous avons des tables d’association pour faire le lien entre les utilisateurs et leurs abonnements.
Les soucis de performance se faisaient ressentir sur certaines requêtes, notamment sur la page d’accueil de l’utilisateur :
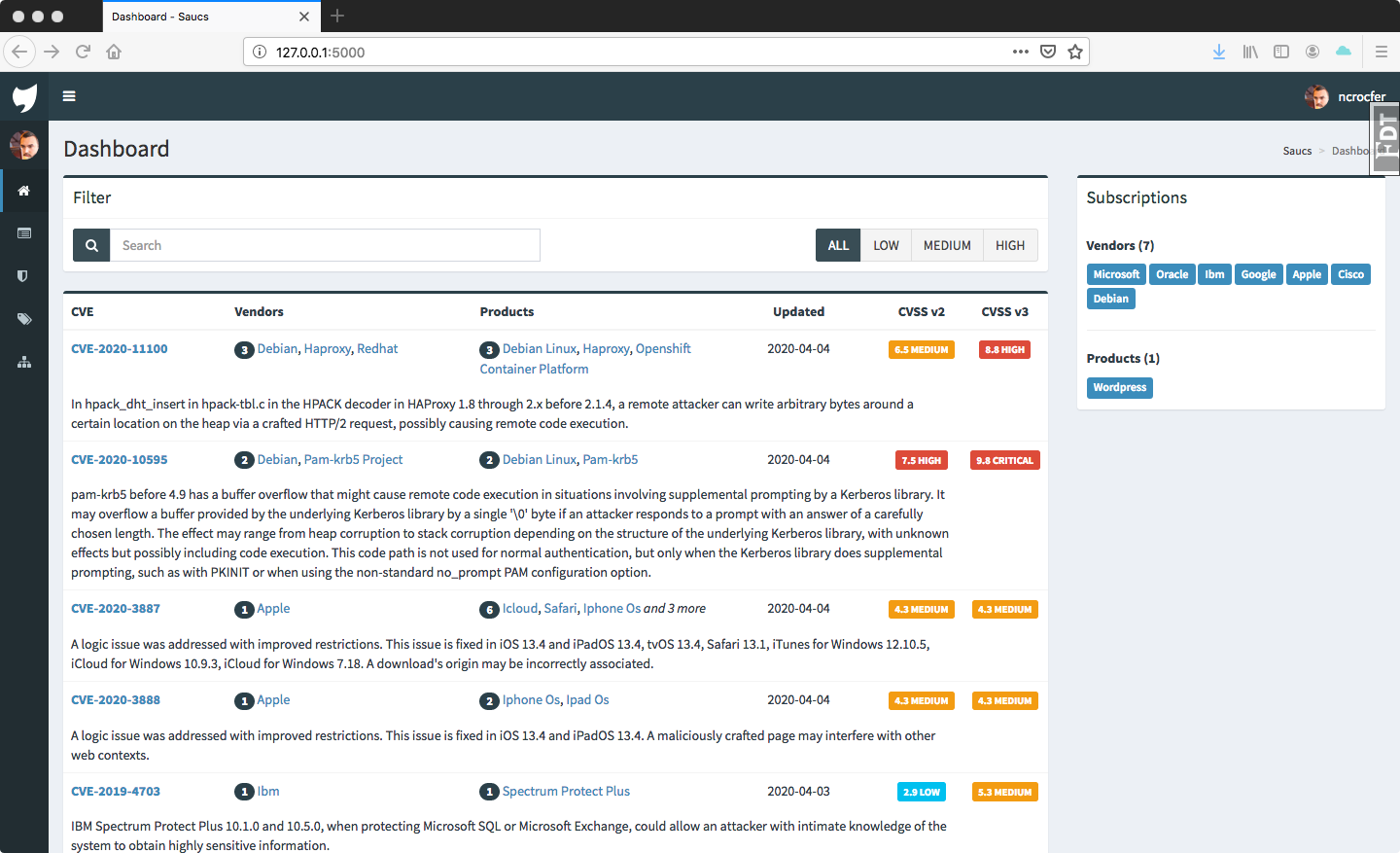
Tout d’abord la requête permettant de retrouver les CVE en fonction des souscriptions de l’utilisateur était assez gourmande :
Cve.query.filter(
or_(
Cve.vendors.any(Vendor.users.any(User.id == current_user.id)),
Cve.products.any(Product.users.any(User.id == current_user.id)),
)
)
La preuve via l’extension Flask-DebugToolbar :
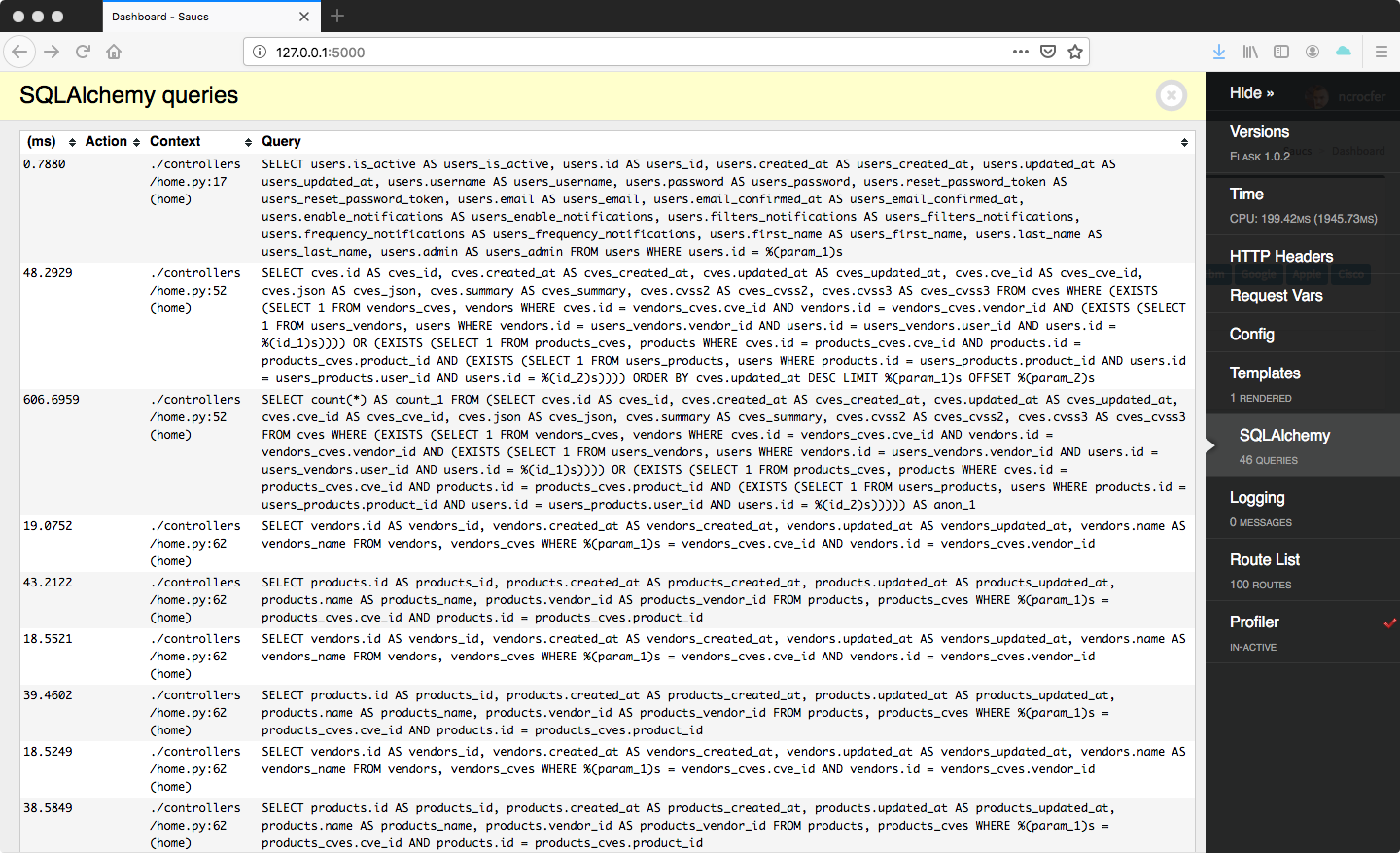
Autre problème comme vous pouvez le constater : la page affiche un extrait des vendeurs et produits affectés par chaque CVE, ce qui implique beaucoup de petites requêtes. Elles ne sont certes pas très gourmandes, mais mis bout à bout le chargement de la page devenait très long.
Avec JSONB
C’est durant mon refacto que j’ai vraiment découvert l’utilisation de JSONB sous PostgreSQL. L’idée était de ne pas stocker ces informations dans des tables d’association mais directement dans la table CVE.
Plusieurs avantages à cela :
- la taille de la database est réduite (à titre d’exemple la taille products_cves contenait environ 350k items)
- la mise à jour des CVE est simplifiée (il fallait jusqu’alors vérifier si l’association existait avant de l’insérer)
- et les performances sont évidemment améliorées
La déclaration sous SQLAlchemy d’une colonne de type JSONB se fait simplement de la manière suivante :
from sqlalchemy.dialects.postgresql import JSONB
class Cve(BaseModel):
__tablename__ = "cves"
...
vendors = db.Column(JSONB)
__table_args__ = (db.Index('cves_vendors_gin_idx', vendors, postgresql_using="gin"),)
L’index de type GIN est très important car il nous fera gagner là aussi un max de perf. Seul inconvénient : l’insertion est apparemment un tout petit peu plus lente. Je dis apparemment car c’est ce que j’ai lu dans la doc mais je ne l’ai pas du tout ressenti durant mes tests.
Pour info mes recherches et mes tests sont partis de ce thread StackOverflow.
Après modification du script d’import les données ressemblent désormais à cela :
$ SELECT cve_id, vendors FROM cves;
...
CVE-2020-3850 | ["apple", "apple-OA-mac_os_x"]
CVE-2020-10865 | ["avast", "avast-OA-antivirus", "microsoft", "microsoft-OA-windows"]
...
La chaîne -OA- est utilisée comme séparateur afin d’inclure les produits dans cette liste (un produit est lié à un vendeur, sans cela des conflits peuvent apparaître car plusieurs vendeurs peuvent avoir les mêmes noms de produits).
La requête permettant d’afficher les CVE propres à l’utilisateur devient alors :
from sqlalchemy.dialects.postgresql import array
Cve.query.filter(Cve.vendors.has_any(array(current_user.vendors)))
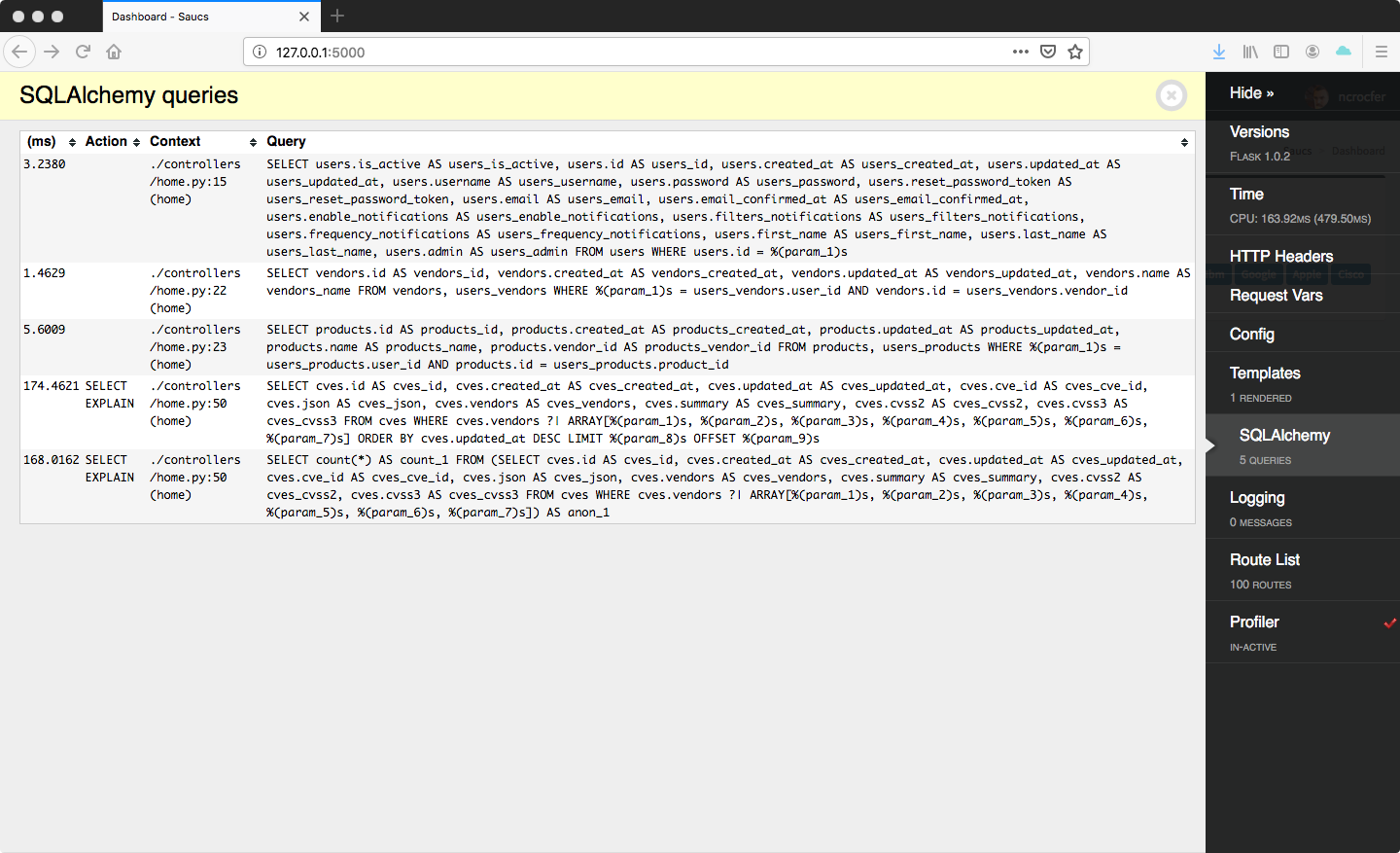
Les performances, notamment grâce à l’index, deviennent vraiment apréciables. De plus nous évitons la multitude de requêtes liées aux vendeurs car l’information est déjà portée par la table CVE :
Conclusion
Comme vous pouvez le voir sur les screenshots je suis passé de plusieurs secondes à quelques centaines de millisecondes. Qui plus est la mise à jour des CVE est vraiment simplifiée.
Nous avons utilisé la méthode has_any() qui permet de renvoyer chaque row répondant à au moins 1 critère. Dans le cas où nous n’aurions qu’un seul item à rechercher (“donnes moi toutes les CVE lié au vendeur debian”) nous pouvons utiliser la méthode contains :
Cve.query.filter(Cve.vendors.contains(["debian"]))
Pour finir il est tout de même important de noter que ce refacto amène un changement majeur : Saucs ne fonctionnera plus que sur PostgreSQL. J’ai décidé d’accepter cette contrainte afin d’améliorer les performances, notre prod tournait déjà sur PG et SQLite n’était utilisé que pour les tests. Il faudra désormais une seconde instance pour les lancer, mais ce n’est pas très grave.
Et si demain quelqu’un trouve une meilleure solution je suis clairement preneur, le projet va devenir opensource et il sera donc bientôt possible de contribuer directement au code :)